图解:SPSS用于倾向得分匹配
2018-09-26 MedSci MedSci原创

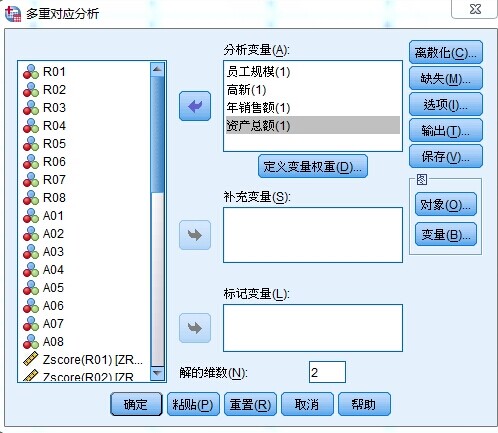
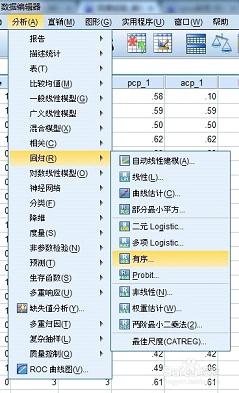
本篇文章介绍如何使用SPSS进行1:1的倾向性得分匹配,这里的1:1指的是两个样本量相同的组,可以分别命名为实验组和对照组;如果实验设计中,样本组的数目多于两个(例如有实验组、对照组和空白组),那么需要用1:m的倾向性得分匹配方法。两者的理论基础其实是类似的,差异在于匹配的数目不同。SPSS只能进行1:1的倾向性得分匹配。后面草堂君会介绍如何使用SAS进行1:m的倾向性得分匹配。 倾向性得分
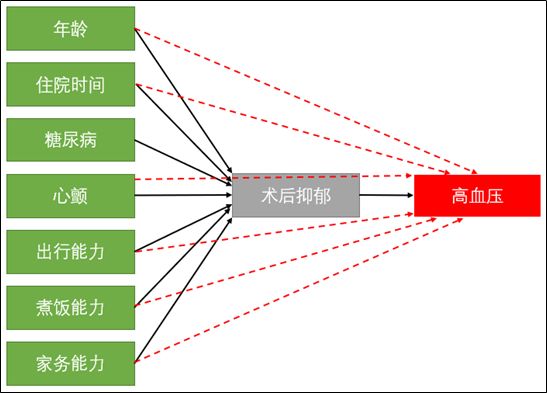
本篇文章介绍如何使用SPSS进行1:1的倾向性得分匹配,这里的1:1指的是两个样本量相同的组,可以分别命名为实验组和对照组;如果实验设计中,样本组的数目多于两个(例如有实验组、对照组和空白组),那么需要用1:m的倾向性得分匹配方法。两者的理论基础其实是类似的,差异在于匹配的数目不同。SPSS只能进行1:1的倾向性得分匹配。后面草堂君会介绍如何使用SAS进行1:m的倾向性得分匹配。 倾向性得分匹配 倾向性得分匹配从名字可知,该方法可以归结为两个大的步骤:1、评定每个研究对象(个案)的倾向性得分;2、根据倾向性得分近似而匹配的原则,对研究对象进行匹配分组。计算每个研究对象(个案)的倾向性得分可以通过logistic回归模型、Probit回归模型和判别分析模型等,最常用的是logistic回归模型,SPSS的1:1倾向性得分匹配就是采用logistic回归模型计算每个研究对象(个案)的倾向性得分。 对于倾向性得分匹配方法的理论,草堂君以下面的例子,再次对其分析逻辑做出解释。如下图所示,某课题组研究术后抑郁与术后高血压是否存在相关关系。分析者采用抑郁量表对研究对象(病人)是否患有抑郁症进行评定
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言