SPSS教程:卡方拟合优度检验(详细版)
2018-11-06 李侗桐 医咖会

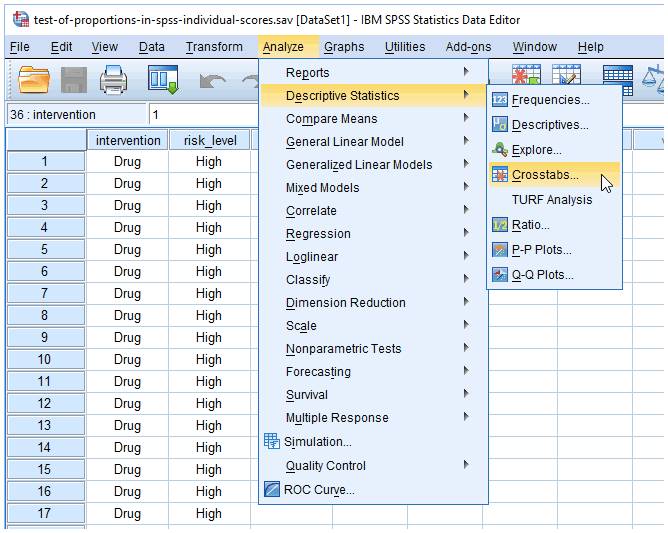
有小伙伴曾经提出过这样的疑问,从下图中SPSS菜单的两个入口进去,都是做卡方检验吗?两者有啥区别? 点击Analyze → Descriptive Statistics → Crosstabs 点击Analyze → Nonparametric Tests → Legacy Dialogs → Chi-square
有小伙伴曾经提出过这样的疑问,从下图中SPSS菜单的两个入口进去,都是做卡方检验吗?两者有啥区别? 点击Analyze → Descriptive Statistics → Crosstabs 点击Analyze → Nonparametric Tests → Legacy Dialogs → Chi-square 经常看医咖会文章的小伙伴应该会注意到,上面第一张图在卡方检验的教程中多次出现,详见: SPSS教程:两个率的比较(卡方检验) SPSS:多个样本率的卡方检验及两两比较 SPSS详细操作:一致性检验和配对卡方检验 SPSS教程:分层卡方检验 那第二张图又是做啥用的呢?下面就让我们进入今天的正题:卡方拟合优度检验(chi-square goodness-of-fit test)——用于检验数据是否服从某个指定分布。 1、问题与数据 某研究者招募了100位受试者,拟探讨体型与参加锻炼意愿之间的关系。但在进行该项目之前,该研究者想知道招募的受试者体型分布是否与总体人群一致。 该研究者已知总体人群中有50%是正常体型(normal),35%为超重(overweight)以及15%为肥
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言