深度:全面剖析倾向得分匹配方法理论及实践
2018-08-22 MedSci MedSci原创

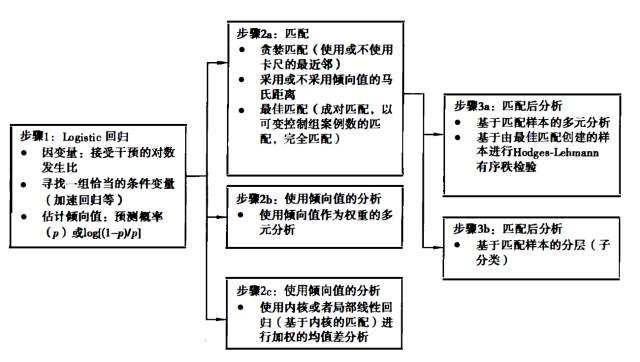
在20世纪30年代之前,匹配法(也称控制法)在因果研究中占据了压倒性的地位,科学家认为只有将实验组和对照组的所有情况都尽可能接近,才能两组间的差异是否归于处理因素。但是,在要让实验组和对照组之前的特征(混杂)尽可能匹配,不仅难以操作,而且会消耗大量资源,尤其在很多情况下,很多因素是试验者难以去控制的。 为什么要做倾向值分析 在卫生领域,随机临床试验(RCT)是应用随机实验法最典型的例子。为
在20世纪30年代之前,匹配法(也称控制法)在因果研究中占据了压倒性的地位,科学家认为只有将实验组和对照组的所有情况都尽可能接近,才能两组间的差异是否归于处理因素。但是,在要让实验组和对照组之前的特征(混杂)尽可能匹配,不仅难以操作,而且会消耗大量资源,尤其在很多情况下,很多因素是试验者难以去控制的。 为什么要做倾向值分析 在卫生领域,随机临床试验(RCT)是应用随机实验法最典型的例子。为了证明某种处理(或因素)的作用,将研究对象随机分组并进行前瞻性的研究,可以最大程度上确保已知和未知的混杂因素对各组的影响均衡,阐明处理因素的真实效应。但RCT对研究对象严格的纳入和排除标准,无疑会影响研究结果的外推,同时费用和组织困难问题很多时候都是让人难以承受的。此外,很多研究问题无法做到随机,甚至有些情况下的随机是违反伦理道德的。 而非随机对照研究(如观察性研究和非随机干预研究)能够较好地耐受RCT中存在的问题,在实际应用中更为广泛。如何利用非随机化研究的资料探究因果,一直是流行病学和统计学研究中非常关注的问题。传统的控制混杂的方法如分层、匹配等控制的混杂因素有限,多因素分析的方法在概念上“控制了
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言




