SPSS分析实战-数据清洗
2020-01-02 万事不惊 简书

这是一篇基于实战的学习笔记 在这个到处都是数据的时代,很多岗位都应该学一点数据分析,不仅是学一个软件,而是要从中掌握数据分析的思维。 问卷调研仍然是广泛应用的数据获取方式,所以学习问卷调研的数据分析不过时。 数据分析只是手段,最重要的还是结合业务场景,懂业务才知道从哪里下手分析。 需要有统计学基本知识,每篇文章前面我会把涉及的统计学知识点列一下,尽量通俗易懂。
这是一篇基于实战的学习笔记
- 在这个到处都是数据的时代,很多岗位都应该学一点数据分析,不仅是学一个软件,而是要从中掌握数据分析的思维。
- 问卷调研仍然是广泛应用的数据获取方式,所以学习问卷调研的数据分析不过时。
- 数据分析只是手段,最重要的还是结合业务场景,懂业务才知道从哪里下手分析。
- 需要有统计学基本知识,每篇文章前面我会把涉及的统计学知识点列一下,尽量通俗易懂。
- 我是一个实践者、也是学习者,有问题欢迎交流探讨。
参考书目
张文彤《SPSS20.0统计分析基础教程第2版》
张文彤《SPSS20.0统计分析高级教程第2版》
软件版本 SPSS25.0
基于电子问卷获取的数据
时间在2019年,问卷调研已经很少采用纸质问卷了,除了一些留置问卷的大型项目,大量线上调研、街头拦截的项目,都采用电子问卷。
电子问卷的好处是,提前可以设置很多逻辑限定,避免了很多人为录入错误。
所以,我的学习基于通过电子问卷获得的数据。
数据清洗
数据分析的第一步是数据清洗,如果你认同这句话,恭喜!你已经具有专业思维了。
本篇用到的统计学知识点:描述统计的基本指标,正态分布
问题1:需要清洗啥?
1.1 查错,通过数据维度找到有问题的样本,并进行标识、处理。调研中常见的问题包括:
- 配额错误
- 答题时间过短
- 样本重复
- 数值问题:异常值、缺失值、错误值
- 前后逻辑矛盾
- 量表题出现大量重复答案,比如全部都选“同意”
1.2 数据形式的再加工,常见情况包括,我下一篇会具体写
- 多选题的预处理
- 开放题的编码
- 选项的重新分组
问题2:技术路线查错
常用的方式基本就是以下几类,根据问题实践一下,很快就可以举一反三:
- 数据菜单:个案排序,汇总、验证、标识重复个案、标识异常个案
- 分析菜单:描述统计
- 转换菜单:对个案中的值进行计数、Recode
- 逻辑语句:IF,Recode,Compute
2.1 配额错误
用描述、交叉表的方式即可,比较简单,不演示做法了。
2.2 答题时间过短
答题时长变量
在线的问卷平台,通常可以提供一个变量是问卷的答题时长,通过这个变量可以初步判断被访者是否认真回答。
合理的答题时间
一个在线问卷调查,设计回答时间的上限通常是15-20分钟,在测试阶段,我会记录一下回答的真实时间,比如10分钟左右。
那么在哪个区间是比较合理的答题时间呢?这是个经验值,也用按后面写道的查找奇异值的方法
问题样本的处理办法
对于回答时间比较短的样本,需要看一下其他问题的回答情况,觉得不太认真的,可以做废卷处理。
有时候也会出现回答时间超长的样本,可能的原因是答题中途有间断,需要根据具体情况再处理。
操作方法
-
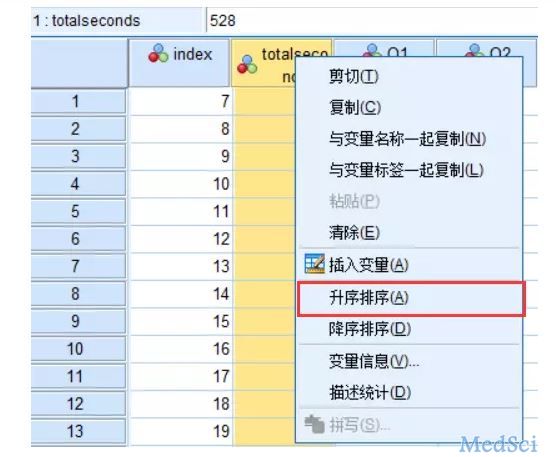
第一步:排序
这是我用问卷星平台做的一个调研,SPSS导入数据以后发现,平台自动生成了一个答题时间变量totalseconds,单位是秒,字符串型变量
在变量视图下
首先要改成数字型变量,否则没法运算,直接改就好。
-
第二步,输出标记
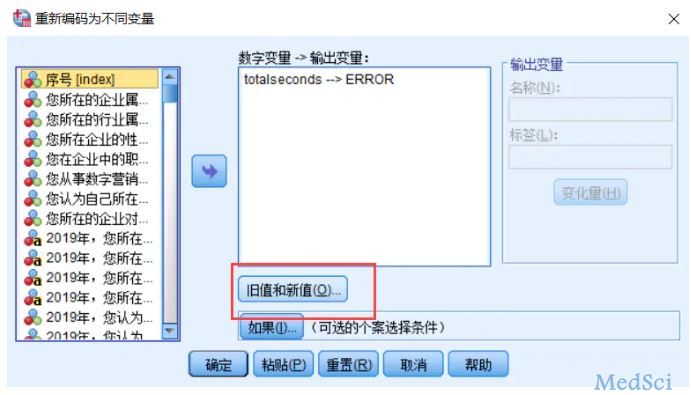
如果确信这个样本可以做废卷处理,可以直接删,或者新建一个二分法变量ERROR,用数值1标记这个样本。因为查错还有很多步骤,可以分别设置变量ERROR1-N,用来标记不同问题。
如果有问题的样本比较少,直接手工录入数值就可以了,如果样本比较多,也可以写个语句。比较方便的是IF和Recode两个语句
把这个语句直接复制到语法对话框里,运行就可以了。
e.g.
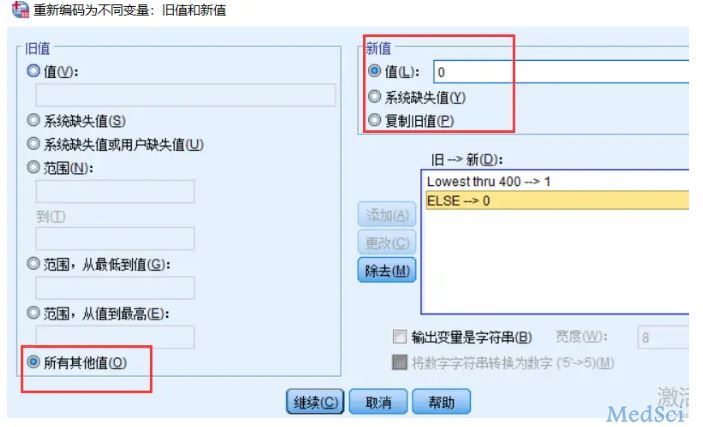
IF totalseconds <=400 ERROR=1.
RECODE totalseconds (Lowest thru 400=1) (ELSE=0) INTO ERROR.

recode的语句比较长,懒得写的话,也可以直接在转换菜单-重新编码为不同变量里操作。
2.3 样本重复
这是手工录入时代常见的问题,电子问卷几乎不会出现了,也学一下吧,万一用得上呢。
操作方法一
数据菜单-汇总
把唯一ID作为分界变量,个案数勾选一下,定义一个新变量名,其他默认就好

跑一下新变量频数,有三个样本是重复了
操作方法二
数据菜单-标识重复个案
把唯一ID作为定义匹配个案的依据,其他默认就好
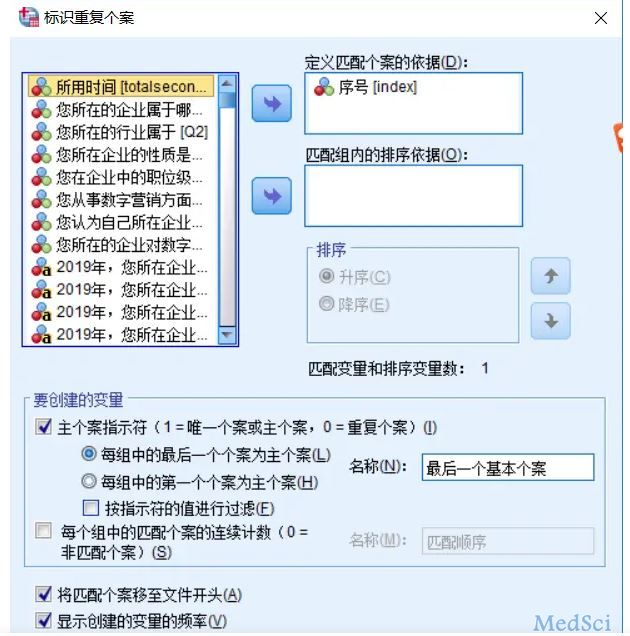
重复个案是2个,由于最后一个个案作为主个案,所以重复的是3个个案。

回到数据视图,系统已经帮你把重复的个案排到前面了,就是它们三个。
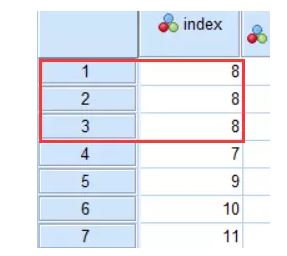
最后视情况处理就好了。
2.4 数值问题:异常值、缺失值、错误值
在电子问卷设计的过程中,我们往往会对每个题是否必答,可填答的数值大小做了限定,所以会大大减少后期出现数值问题的可能。提醒一下,选择题,一定要有一个“不知道或者无法作答”的选项,这样可以封闭选项,使被访者不会因为无法作答而乱答。
尽管如此,仍会有异常值、缺失值、错误值的出现,请看处理方法
2.4.1异常值
方法1:在数据服从正态分布的情况下,可以使用Z分标准化法(3δ法):±3δ (正负3个标准差)以外的数据为高度异常值
这个方法要求数据服从正态分布, 而且不直观,所以只看一下简单演示。
首先要看数据是否为正态分布,方法可以看偏度、峰度、做直方图、做Q-Q图等
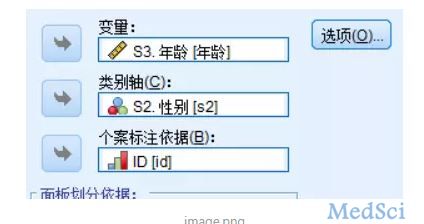
第二步,在描述里,将标准化值另存为变量,找正负3以外的数据。
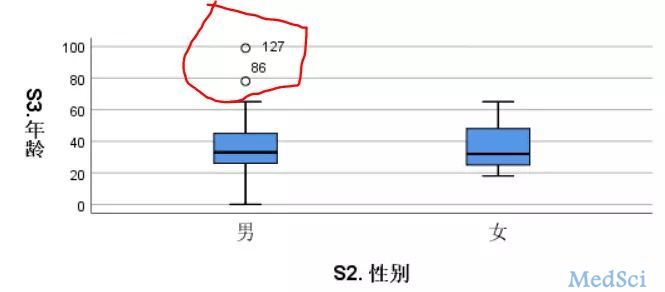
图形-旧对话框-箱图
标识出的ID号就是异常值
方法3:标识异常个案
数据-标识异常个案模块来操作,这部分是通过算法来查找异常值,只能作为参考,而不能作为唯一标准。比如我们举的这个例子,这几个样本都不算异常。
算法基本原理
- 聚类:将所有个案分为若干类
- 评分:对每一个个案在其所属类别的异常度进行评分,并计算相应的异常Index
- 报告:对每一个异常个案,列出导致异常的具体变量的情况
操作方法
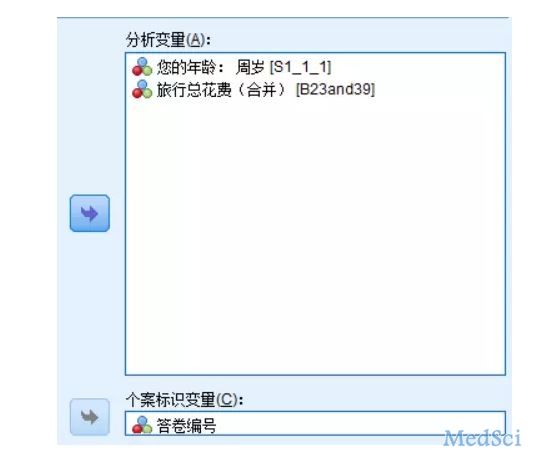
关键是输出结果的解读
异常指标(翻译得不好,就是异常index),这个表的分值不高。
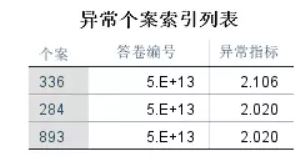
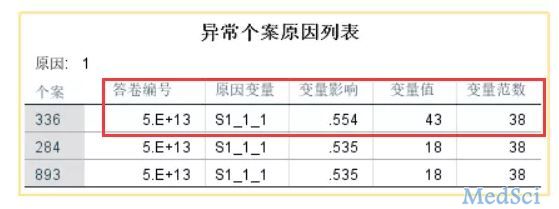
对等ID,说明聚了两类,这几个异常值都属于第二类

算法认为这个变量异常的原因主要是第一个变量,这个个案的变量值是43,变量范数(这个类的变量均值)是38,其实不算异常。
2.4.2缺失值
对于调研数据,如果样本量够,一般缺失值就按缺失处理。样本量少的话也可以用均值替代法处理

2.4.3错误值
在纸质问卷调研中,经常会由于录入错误出现错误值,电子问卷这类问题相对少。
处理方法可以用函数,或者验证模块,参见2.5逻辑矛盾的处理。
2.5 前后逻辑矛盾
问题之间会有一定自然逻辑关系,比如年龄太小不应该有孩子。有时候,我们在设计问卷时也会故意设置一些问题之间的逻辑,以检查回答问题的质量。
方法一:验证模块
比如年龄和婚育状况之间的逻辑
Q1年龄变量的取值是18-45
Q28婚育状况变量的取值是

假设20岁以下有孩子的概率应该非常小,那么逻辑就是
Q1=18或19,Q28不能等于3
第一步先定义规则
数据菜单下的验证模块

选交叉变量规则,注意表达式的意思是错误的逻辑,别写反了
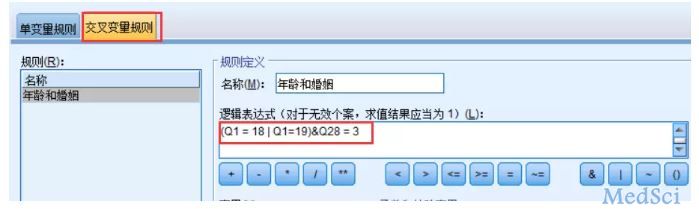
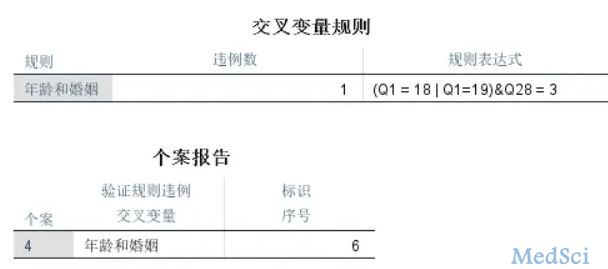
第二步在验证模块里选验证数据

输出的结果就可以直接显示逻辑错误的样本了

方法二:函数
e.g.
IF(Q1=18 | Q1=19)&Q28 = 3 ERROR=1.
有时候也会用到compute
2.6 量表题答案重复
量表题如果大量答案重复(比如都选同意),一方面反映这个样本的质量可能有问题,另一方面,在做因子分析的时候也会影响结果。可以用计数的方法查错。
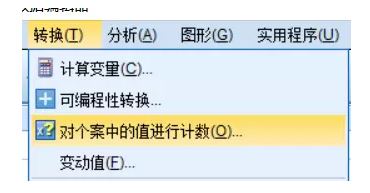
第一步,定义一个新变量,把量表的语句都选进去

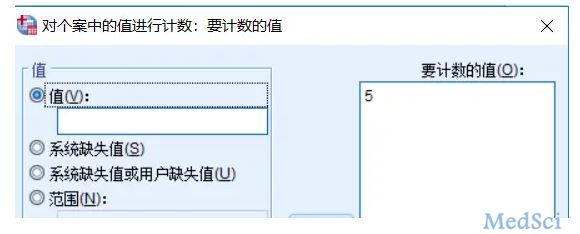
第二步,统计选5(非常同意)的个数
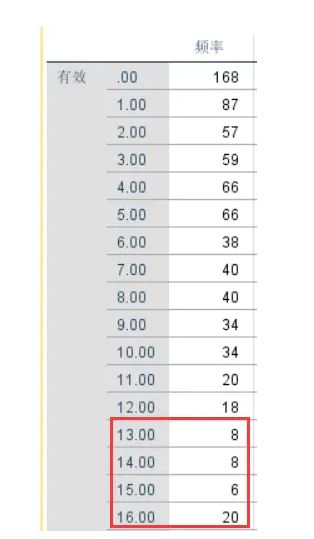
第三步:跑一下新变量QT的频数,看到一些样本的答案大量集中于5
第四步,处理方法
看一下这些样本的整体回答情况,如果其他问题不大,问卷可以保留,但在做因子分析的时候,需要过滤掉,如果其他题回答的也很不认真,就可以当作废卷处理了。
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言




#数据清洗#
45
#清洗#
39