单因素分析和多因素分析的结果不一致,咋整?
2018-10-14 龚志忠 量化研究方法

我们在做统计分析时,很多人都习惯这样的分析套路:先进行统计描述,然后做单因素分析,最后再进行多因素分析。在阅读文献时,我们也会发现,不管是一般的统计描述还是单因素分析,往往能够支持研究人员作出结论的,还是要看最终的多因素分析结果。在前期推送的内容中我们也讲过,多因素分析的目的是通过控制其它多个混杂因素的影响,找出具有独立作用的影响因素,并估计其效应大小。既然这样的话,做单因素分析还有什么用呢,
我们在做统计分析时,很多人都习惯这样的分析套路:先进行统计描述,然后做单因素分析,最后再进行多因素分析。在阅读文献时,我们也会发现,不管是一般的统计描述还是单因素分析,往往能够支持研究人员作出结论的,还是要看最终的多因素分析结果。
在前期推送的内容中我们也讲过,多因素分析的目的是通过控制其它多个混杂因素的影响,找出具有独立作用的影响因素,并估计其效应大小。
既然这样的话,做单因素分析还有什么用呢,直接做多因素分析不就好啦?
多因素分析的地位固然重要,但是单因素分析也必不可少,单因素分析可以为多因素分析提供很多有效的信息,将单因素和多因素分析的结果进行比较,也能发现很多问题。如果单因素和多因素分析的结果一致的话,结论就比较稳定且容易解释,但是我们常常会遇到单因素和多因素分析的结果不一致,甚至是出现相互矛盾的尴尬情况,此时又该怎么办,该如何去解释呢?
今天我们就来一起聊一聊单因素分析和多因素分析之间的爱恨情仇。
首先我们根据单因素分析和多因素分析的结果对比,将可能出现的情况做一个四格表,如表1所示,分为A、B、C、D一共4种情况,下面我们分别对这四种情况进行讨论。
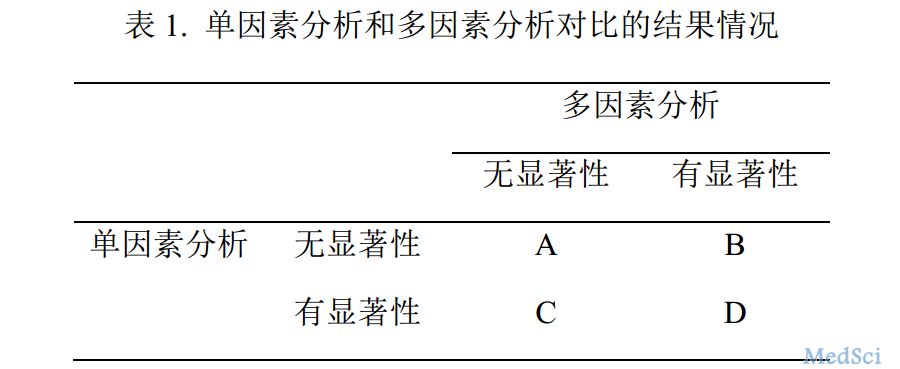
情况 A
单因素分析和多因素分析的结果都显示无统计学显着性,两者结果一致,均为阴性结果
在这种情况下,结果还是相对比较好解释的,一般基本上可以认为该因素对于结局事件来说,不是一个有意义的影响因素。
但是事情也并非这么简单,如果该因素作为一个混杂因素,在多因素分析中只是用来起到调整混杂作用的目的,那么虽然它在单因素和多因素分析中都是阴性结果,可能也不会太引起研究人员的重视;但是如果该因素是研究中所重点关注的一个因素,例如暴露/处理因素,此时单因素和多因素分析都得出阴性结果的话,就会让人感觉比较沮丧,不过也更值得我们好好去思考一下阴性结果背后的意义。
到底是该暴露/处理因素对结局事件真的没有影响,还是说因为其他原因而导致它的实际效应没有被显示出来?到底是研究设计的问题,还是指标定义的问题,亦或是统计方法的问题呢?都需要我们认真去查找一下原因,可以参考前期推送的有关文章,或许可以帮助你寻找一下产生阴性结果的原因,开拓一下分析思路。
情况 B
单因素分析结果显示无统计学显着性
但多因素分析结果显示有统计学显着性
这种情况可能并不常见,主要是因为在单因素分析中没有统计学显着性的因素,按照一般的做法就不会再将此变量纳入到多因素分析中了,但其实上述做法小咖并不推荐,它是存在一定缺陷的。
我们在前期介绍《如何理解回归模型中的“调整”和“独立作用”》的内容中讲到,在单因素分析中,由于自变量之间存在一定的相互关联,自变量对因变量的影响反映的不仅仅单纯是它本身的作用,而是包含了该变量自身作用以及其他变量的混杂作用之后,呈现出来的一个综合的结果。而在多因素分析中,通过构建回归模型,调整了其他混杂因素的影响,从而才使该因素对因变量的真实效应显示出来。
因此不难理解,当某因素在单因素分析结果中无统计学显着性,而多因素分析结果有统计学显着性时,此时可能的原因是,该因素与其他混杂因素之间可能存在一定的关联,在单因素分析时,该因素的真实效应被其他混杂因素的作用所掩盖,通过多因素分析消除其他因素的影响后,才发现原来该因素对于结局事件来说是具有独立作用的。
举一个例子,例如某因素A是一个危险因素,而因素B是一个保护因素,由于具有因素A的个体,大部分人同时也具有因素B,因此在单因素分析中,因素A的作用并没有显现出来,这是因为因素A的危险作用被因素B的保护作用所掩盖了,无法体现因素A的实际效应。而通过多因素分析,将因素B的保护作用进行调整,从而暴露出因素A真实的危险作用。
情况 C
单因素分析结果显示有统计学显着性
但多因素分析结果显示无统计学显着性
想必大家都会经常遇见到这种情况,单因素分析时该因素有统计学显着性,然后就很兴奋地把它扔进多因素分析中,结果多因素分析结果却显示没有统计学显着性,感觉前功尽弃,很让人头痛,不知道是出了什么问题,到底该怎么办了。
我们仍然以前推送的《传统单因素分析和单因素回归分析》一文中所引用的研究为例,如表2和表3所示。
表2. 研究对象基线特征
表3. 单因素和多因素Cox回归结果
最后作者又进行了多因素回归分析,结果显示Non-HDL-C对于心血管疾病发生的影响消失了,没有统计学显着性,HR=1.77,95%CI为0.98-3.15(P:No Significance)。为什么会出现这样的情况呢?
如果你对情况B产生的原因已经理解,那么情况C也是同样的道理。在单因素分析中,自变量与因变量之间可能出现一定的假关联或者是间接的关联,例如某因素A对结局事件并无影响,而因素B对于结局事件是一个影响因素,但是由于因素A只是单纯的和因素B有强烈的相关性,两者存在共线性的现象,那么在单因素分析中,就可能出现因素A也存在显着差异的结果,从而导致因素A被误认为是一个影响因素而纳入到多因素分析中。
而在多因素分析中通过调整因素B的影响,因素A与因变量的“假关联”就消失了,此时可以认为因素A实际上对于结局事件并非是一个影响因素。就如同上述研究中的Non-HDL-C这个指标,在单因素分析中,它与心血管疾病的关联受到其它因素的影响,可能只是一种“假关联”,这种“假关联”在多因素分析中就很容易被调整而消失。
(注:针对Non-HDL-C这个指标,本文只从统计结果的角度将该研究作为例子进行讲解,不对Non-HDL-C作专业上的解释,具体意义需结合临床)
情况D
单因素分析和多因素分析的结果都显示统计学显着性,两者结果一致,均为阳性结果
这种情况应该是大家最愿意看到的情况吧,往往单因素和多因素分析都出现阳性结果,以此结果作出的结论还算是比较稳定可靠,可以放心地写文章投稿了,但前提是单因素和多因素分析的阳性结果的方向是一致的,比如单因素分析显示病例组某因素的水平显着高于对照组,多因素分析也显示该因素为危险因素,两者的结果都倾向于该因素对结局事件具有危险作用。
不过偶尔也会遇见这样的情况,虽然单因素和多因素分析都得出阳性结果,但是有时单因素分析显示为危险因素,而多因素分析显示为保护因素,或者单因素分析显示为保护因素,而多因素分析显示为危险因素,两者的结果是相互矛盾的。
出现这样的情况,其实和上述的情况B和C是同样的道理,这是在统计分析中经常出现的一个陷阱,统计学上称之为“辛普森悖论”(Simpson’s Paradox),是由英国统计学家E.H.Simpson于1951年提出。简单理解就是,在某个条件下的两组数据,分别讨论时都会满足某种性质,可是一旦将两组数据合并考虑,却可能导致相反的结论。
我们今天讨论的单因素分析和多因素分析的结果出现不一致的情况,就是一个典型的“辛普森悖论”的例子。在单因素分析中,由于没有考虑到其他因素的影响,在一定情况下就会发生“辛普森悖论”,然而在多因素分析中,通过调整控制其他因素的影响,就可以解开“辛普森悖论”之谜,这也是一个很有意思的现象。有兴趣的小伙伴可以先查阅一下有关“辛普森悖论”的资料,我们将在以后的内容中向大家进行介绍。
小提示:本篇资讯需要登录阅读,点击跳转登录
版权声明:
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言








#单因素分析#
40