
重症医学随机试验中的功效偏倚和临床重要疗效
2023-02-08 网络 网络 发表于上海

本研究评估了高影响力重症医学试验中的功效偏倚(powering bias)以及掩盖临床重要疗效的有关风险。


武汉大学中南医院 祝媛/彭志勇 译
中山大学附属第一医院 吴健锋 审
中国医学科学院北京协和医院 杜斌 述评
武汉大学中南医院 祝媛/彭志勇 述评
目的:临床试验设计中反复出现的一些问题可能会使结果偏向无效, 导致疗效不确定。本研究评估了高影响力重症医学试验中的功效偏倚(powering bias)以及掩盖临床重要疗效的有关风险。
设计、地点及患者:以病死率为主要终点的重症成人多中心随机试验进行二次分析。纳入2008年至2018年顶级期刊发表的临床试验。分析评估了对照组预期病死率的准确性、自适应样本量策略、预期疗效的合理性及最小临床意义变化值的相关结果。主要研究结果为研究特定随访期内的死亡风险差。
干预:无
指标和主要结果:在纳入的 101 项试验中,12 项试验的主要终点指标有统计学差异,其中5项试验存在干预相关的病死率升高。大多数临床试验(77.3%)在功效计算时都高估了对照组病死率(实测值减去预期值的差值,-6.7% ± 9.8%;P < 0.01)。在 14 项试验中,由于对照组病死率的错误估计,干预措施需要预防至少半数的死亡才能达到预期疗效。7 项试验预设了自适应样本策略,可能会减少这一情况。20项试验的实测病死率风险比其预期病死率风险低约 5%,其中有16项试验并未达到统计学差异。近半数试验(47.0%)预设绝对风险降幅至少为10%,但其中只有 3 项试验在统计学意义上达到了该疗效。大多数试验(67.3%)都不能明确临床重要治疗是否获益或损害。
结论:大多数高影响力重症试验设计会高估对照组病死率,增强不真实疗效,从而使结果偏向无效。临床重要疗效通常不能明确。(Crit Care Med 2020;48:1710-1719)
关键词:偏倚;临床试验主题;重症;最小临床意义变化值;样本量
无统计学意义的临床试验结果并不能排除可能有重要的临 床发现。那些未显示出统计学显著治疗获益的“阴性”的随机对照试验(randomized controlled trials,RCTs)在某些情况下可能的确反映了对试验人群治疗普遍无效。但“阴性”RCTs也可能是设计选择的产物,掩盖了在研究人群中的重要疗效。评估重症患者治疗相关 RCTs 为质疑试验设计提供了理想的学习案例。表型异质性 [4-7]、操作差异 [8-9] 和重症疾病病死率长期趋势 [10] 都可能导致对照组病死率和疗效大小的不准确预估,这反过来会影响统计学功效。重症疾病的复杂性和竞争性风险的普遍性导致临床试验通常不会采用除全因病死率以外的终点指标。试验可能会追求过于乐观的疗效,发现不了临床上重要的微小差异,或是为了纳入多个临床中心和一定时间获得较大样本量而消耗大量资源,两者都不理想。
功效和样本量可以导致“阴性”的试验结果,该研究为明确被反复提及的功效和样本量估算问题,评估了顶级医学期刊发表的多中心重症 RCTs,以及这些试验是否可靠地排除了重要的临床生存差异。研究的主要假设是两个老生常谈的问题:对照组病死率的错误估计和过于乐观的预期疗效,这可能使得试验结果偏向无效。该研究还评估了试验结果未能排除潜在临床重要疗效的概率。
材料和方法
试验纳入标准
符合纳入标准的研究为以病死率为主要终点的重症成人多中心RCTs。纳入的试验必须于2008年1月至 2018年12月期间由7大高影响力的综合医学或专业期刊发表,包括:新 英格兰医学杂志(New England of Respiratory and Critical Care Medicine)、美国医学会杂志(Journal of the American Medical Association, JAMA)、 柳 叶 刀(Lancet)、 美国呼吸与重症医学杂志(American Journal of Respiratory and Critical Care Medicine)、柳叶刀呼吸医学(Lancet Respiratory Medicine)、 重症监护医学(Intensive Care Medicine)和重症医学(Critical Care Medicine)。为识别出最能影响未来试验设计和临床实践的试验,根据影响因子和内容相关度选择了如上期刊。本研究排除了非优效性设计或未采用随机化的试验。
数据提取
由2名研究人员独立筛选每个期刊的目录,并通过PubMed检索来确定纳入的文献 (附录,补充数据内容 1,http://links. lww.com/CCM/F818)。所有不同检索策略的结果都由第3位独立审查员来整合并建立最终研究清单。
数据提取使用双重盲法,由第3位独立审查员解决不一致的条目。数据来源包括主要的试验发表文章、附带的在线数据和方案补充、已发表的试验方案和在线试验注册网站。
主要结局
本研究的主要结局为各项试验特定的初次随访期间未校正病死率风险差(治疗组减去对照组)。
最小临床意义变化值的确定
从临床医生角度,最小临床意义变化值(minimal clinically important difference,MCID)是改变 1 个患者的常规临床实践的最小疗效 [11]。根据 MCID 的现有文献 [12-17],同时考虑到较小的差异不太可能改变临床实践,本试验预设绝对病死率风险差为5%,相对病死率风险差为 20%。在二次分析中还考虑了其他的MCID阈值(附录,补充数据内容 1,http://links.lww.com/CCM/F818)。
统计分析
由各项研究报告的样本量计算获得对照组预期病死率和预期风险差。由各项试验观察到的入组情况和病死率来计算实测风险差。根据提取数据计算出相应的 95% 置信区间(confifidence interval,CI)。
将各项试验的实测病死率和预期病死率做配对处理,通过配对t检验确定各项试验对照组的实测病死率和预期病死率差值的均数与零是否有显著性差异。
为评估对照组病死率的错误估计对统计功效的影响,将预期绝对死亡风险降幅作为对照组实测死亡风险的一部分进行评估。用样本量和相关风险制图,通过图像评估对照组病死率和 统计功效间的联系。
根据Kaul和Diamond的方法 [18] 评价有重要疗效结论的试验结果。试验评价包括各试验风险差的 95% CI是否包括 MCID及其预期疗效。贝叶斯模型采用马尔科夫链蒙特卡罗方法,具有无信息先验、1,000次老化迭代、50,000次迭代和5%减薄率的特点。模型结果用于计算在绝对和相对风险范围内观测到预设MCID的后验概率。本研究将报告各项试验疗效的后验概率。 在二次分析中会考虑其他临床重要疗效的阈值(附录,补充数据内容 1,http://links.lww.com/CCM/F818)。
频率假设检验未对多重比较进行校正,将双侧显著性水平设为 0.05。使用 SAS 9.4(SAS Institute Cary, NC)和 PASS 14(NCSS, LLC, Kaysville, UT)进行分析。
结果
纳入试验特征
在初筛的657项试验中,最终纳入了101项患者随机且以病死率为主要终点指标的多中心优效性试验(表1和附录图 1,补充数据内容 1,http://links.lww.com/CCM/F818)。纳入试验的完整目录详见在线附录(补充数据内容 2,http://links.lww.com/CCM/F819)。12项(11.9%)试验的主要终点有显著性差异,其中5项试验结果表明干预增加了病死率。
样本量
用于主要终点分析的样本量中位数 [ 四分位数(interquartile range,IQR)] 为 843(411~1,588)例患者(附录表1,补充数据内容 1,http://links.lww.com/CCM/F818)。样本量最小为62例患者,最大为20,127例患者。7 项(6.9%)试验方案采用了自适应样本量设计,当达到预设标准时允许增加纳入样本数量 [19-24]。
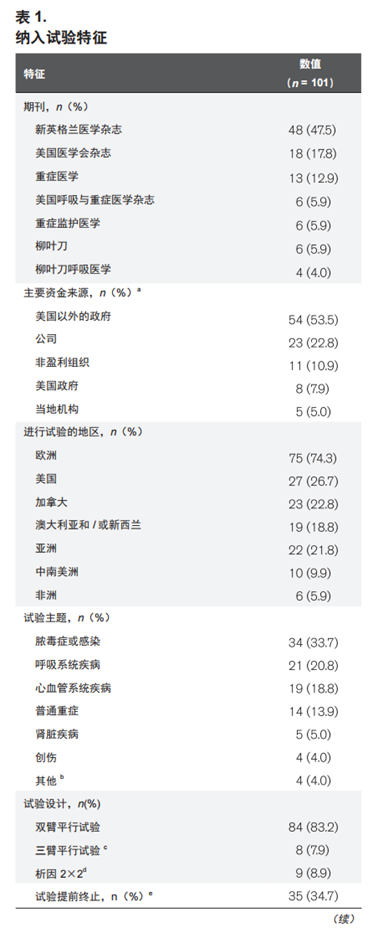
对照组病死率
在101项试验中,97项试验报道的功效计算数据足以计算出对照组的预期病死率,其中位数(IQR)为40%(35%~45%)。
功效计算明显高估了对照组病死率(实测值:33.9%±18.0%;预期值:40.6% ± 17.5%;均数差:-6.7%±9.8%;P < 0.01)。75项试验(77.3%)高估了对照组病死率,只有22项(22.7%)试验低估了对照组病死率。各试验类型的对照组病死率准确性详见附录表 2(补充数据内容 1,http://links.lww.com/CCM/F818)。
预期风险差
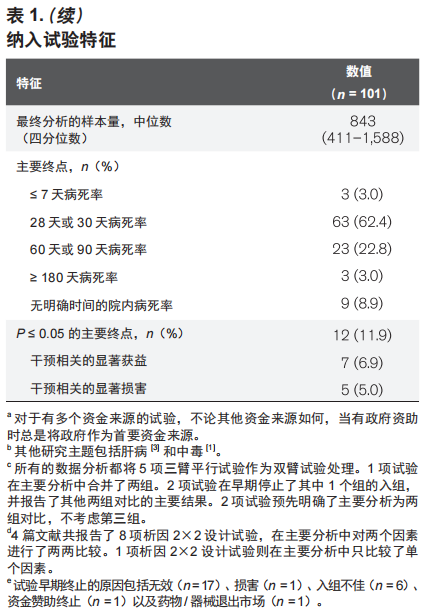
在绝对风险中,各试验拟测得的病死率风险差中位数(IQR)为 9.0%(6.0%~12.0%),相当于需治疗人数(number needed to treat,NNT)为 11[8-17]。仅 19 项试验(19.0%)拟测得的风险差小于等于 5%(NNT = 20)(图2)。纳入的所有期刊和疾病的 预期样本量都较大(附录图2、图3和附录表3,补充数据内容1,http://links.lww.com/CCM/F818)。
在相对风险中,各试验拟测得的相对风险降幅中位数(IQR)为 23%(20%~30%)。19 项试验中,预期相对风险降幅超过了总死亡的三分之另5项试验中则超过半数。
对照组病死率的错误预估对预期疗效的影响
预期病死率是试验中对照组实测风险基线的百分比,其绝对风险降幅中位数(IQR)为 28.7%(20.1%~42.5%)。考虑对照组的实测病死率,为达到预期绝对风险降幅,14项试验的干预必须要预防半数以上的死亡,这是几乎不可能的疗效。而在另2项试验中,即使干预能预防所有的死亡也不可能达到预期的绝对风险减少率。
实测风险差
实测风险差(治疗组减去对照组)的中位数(IQR)为 -0.2%(-1.7%~2.0%),区间范围为-16.7%~11.7%(图 2)。
在疗效有统计学意义的试验中,实测风险差中位数(IQR)为 -9.1%(-13.1%~ -1.5%),相当于预防1例死亡的NNT中位数(IQR)为 11(8~68)。
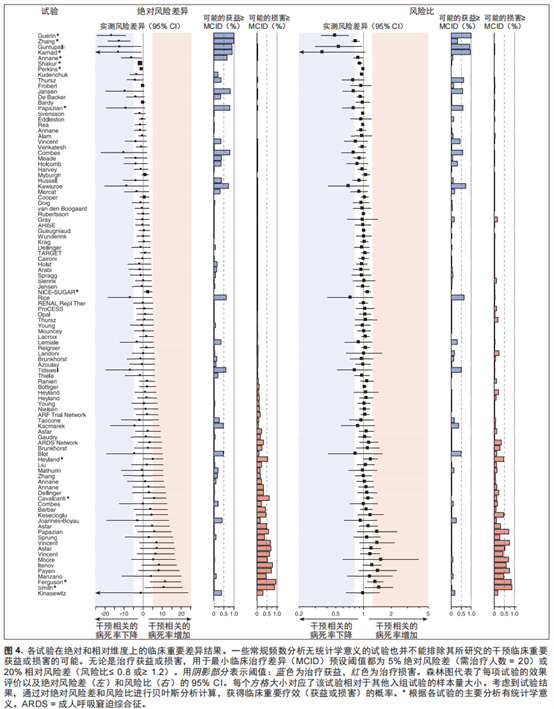
只在5项试验 [25-29](5% 的纳入试验)中观察到绝对风险降幅≥ 10%(NNT ≤ 10),其中2项并未达到统计学差异 [26,27]。 5项试验治疗获益如此大,但其中4项试验在所有试验样本量排序最小的三分之一内,其 CI 也相应较宽,让人不禁对其优异的疗效产生怀疑(图4)。
疗效的临床意义变化值
100项试验中只有 20 项试验必要数据完整,其实测死亡风险差在预期疗效 ± 5% 范围之内。但20项试验中有 16 项试验的主要终点未达到统计学差异(图2和附录表4、表5,补充数据内容 1,http://links.lww.com/CCM/ F818)。样本量越大,实测疗效和预期疗效之间的差异就越小(皮尔逊相关系数=-0.42;95% CI,-0.57~-0.24;P < 0.01)。
无效试验 94项试验中,有21项试验(22.3%)疗效无统计学意义,其风险差的 95% CI 包括试验拟检测的疗效大小。44 项(46.8%)试验的 95% CI 包括了5%的死亡绝对风险降幅(图4),即用于分析的先验 MCID。
无害试验 96项试验中,49项(51.0%)试验的病死率在干预后没有显著恶化,其 95% CI 包括5%的死亡绝对风险增幅,即 MCID(图4)。与获益和损害相关的其他风险差阈值重复内容详见附录(附录表6~ 表8,补充数据内容 1,http://links. lww.com/CCM/F818)。
重要疗效的不确定频率结果 通过评估95%CI是否包括了5%的获益或损害绝对风险差,从而评估试验疗效大小。在101项试验中,有68项试验(67.3%)结果无统计学意义,不能得出临床重要治疗获益或损害的明确结论。
重要疗效的不确定贝叶斯结果11项试验中,相较于不降低死亡风险(后验概率 > 0.5),干预更可能降低至少5%MICD(治疗获益)的死亡风险,其中6项试验并未达到统计学差异(图4)。11项风险中,干预更可能增加至少5% MCID(治疗损害)的死亡风险,其中7项试验并未达到统计学差异。按期刊和疾病分类的结果详见附录图4和图5(补充数据内容1, http://links.lww.com/CCM/F818)。 其他疗效、各试验的后验概率以及绝对风险差和风险比详见图4和附录图6~图9(补充数据内容1,http://links.lww.com/CCM/F818)。

讨论
本研究发现多中心重症 RCTs 通常会高估对照组病死率,对疗效过于乐观,并且不能提供临床重要生存差异的确定性结论。这些问题可以统称为“功效偏倚”。
与临床医生的相关性
这些结论对寻求基于循证医学实践的临床医生具有重要意义。尤其在重症医学领域,一两项试验结果就能决定一项治疗是否能得到广泛应用 [30-33]。当一项大型试验主要终点无统计学差异时,通常认为这种疗法是无效的,不会应用于临床实践。如果试验结果能确定排除MCID和其他偏倚的影响,这种看法也许是合理的。但目前的研究表明,无论真实疗效如何,大多数重症多中心RCTs都存在对疗效的过分高估和对照组病死率的错误预估,二者共同导致了试验结果偏向无效。因此,由于功效偏倚,我们认为这样的试验结果是不确定的。
因此,临床医生必须学会通过评估功效偏倚,权衡循证证据进而指导临床决策,这是一项必备技能。评估试验偏倚的经典方法 [34,35] 通常不包括评估检验功效和样本量计算相关的潜在偏倚,但这些偏倚很常见,并可能使试验结果偏向无效。
为确定功效偏倚的影响,目前的研究提出了当阅读试验报告时应注意的两个简单问题。 一是用于样本量估算的预期对照组病死率是否高于试验中的实测对照组病死率?二是试验拟检测的疗效大小是否不包括让临床医生改变临床实践的MCID?如果对任一问题持肯定回答,那么就可能存在功效偏倚。尤其是当疗效的95% CI包括MCID时,最好将“阴性”试验定义为不确定的试验。总之,应该结合试验结果(获益和损害)、现有文献以及对病理生理的理解来解释试验结果,并衡量是否应用于临床。
与试验人员的相关性
本研究也强调了在试验规划时应考虑的几个问题。即使有严格的试验合格标准和标准化的护理方法,也很难减少重症监护中固有的表现[4,6,36]和操作异质性[37]。这种异质性和病死率的长期趋势[10]可能共同导致了对照组病死率的高估。
重症临床试验通常对疗效过于乐观。本研究中近半数(47%)的试验拟降低至少 10% 的绝对病死率;但只有5项试验有这种疗效,其中4项试验的样本量中等(114~466 例患者)且 95% CI 较宽,提示我们其真正的疗效可能更小。因此,旨在检出死亡风险差异超过10% 的试验可能偏向于“阴性”结果,需要其他令人信服的理由才能继续试验。
有几个因素可能导致过分乐观的预期疗效,包括:1)需平衡样本量、预算限制以及试验可行性之间的关系;2)现有文献的发表偏倚;3)当早期试验出现明显结果时,可能会导致高估疗效,但最可能的是被资助进行大规模试验 [38-43]。并不是所有因素都对疗效本身
过于乐观(乐观偏倚[38]),因此,不管是什么原因导致这种过分夸大的预期效应,都可以使用“增量通货膨胀”这一术语来评估[13]。为检测接近 MCID 的风险差的大样本试验通常需要增加临床中心或延长试验的入组时间,这可能会给试验引入额外的表现和操作异质性。大样本试验的成本可能高得吓人,也减少了特定资助机构资助的研究数量。
由于疾病特殊性或大多数危重疾病缺乏可替代的中期终点[44],全因病死率仍然是 III 期临床试验中应用最广泛的重症治疗终点。但病死率并不总适合作为试验的主要终点[45]。相对风险降幅可以说明死亡风险基线值的大小,当预期死亡风险基线值太低时,病死率并不适合作为主要终点。例如当对照组病死率为15%时,为检测出 5% 的绝对死亡降幅,治疗需要预防三分之一的死亡才能达到统计学差异,在本研究中只有3项试验达到了这种近乎不可能的疗效。在某些情况下,可以将绝对风险降幅控制在5%内,从而将预期相对风险降幅控制在合理范围内。仅仅招募高死亡风险的患者并不能提高试验效果,反而会稀释特定疾病和靶向的归因风险,也就是因为特定疾病和靶向机制导致的死亡比例[46-48]。
解决试验设计和报告中的功效偏倚
自适应试验设计和基于 MCID 的报告可以减少功效偏倚, 但这两项策略尚未得到广泛应用。
自适应试验设计可以克服对照组病死率的错误估计的影响[49],但在本研究中只有 6.9% 的研究运用了该策略。任何类型的自适应试验设计都要求资金和监管机构有一定的灵活性,能够考虑到并响应样本量增加,并且注意避免引入偏倚 [50,51]。
试验分析方案应包括评估与预设 MCID 相关的临床重要性,以促进对临床实践的解释。我们推荐使用两种策略(图 4)[18]。一是当效应评估的 95% CI 相对于 MCID 下降时,应该在文中报道[52,53]。 如果95% CI 包括MCID,就不能排除其临床重要性,应该认为其结果是不确定的[54]。二是计算超过或等同于 MCID 的有关疗效的贝叶斯后验概率[55]。通过无信息先验假设,仅由试验数据计算出有效后验概率,这种方法比需要各种特定信息的贝叶斯先验更广为人知。统计结果可以指导临床实践,即基于各项试验结果评估临床重要疗效的可能性。在试验方案中应该预设 MCID,并且对获益或损害 MCID 都进行评估。在试验设计中纳入MCID也许可以帮助建立标准,促进资助机构资助更多完善和具有临床意义的试验。
不足之处
本研究并不是第一个探索功效偏倚有关的研究[12,13,58]。但本研究证实了在近年来重症临床研究中存在着功效偏倚。本研究以现有文献为基础,通过MCID评估这一问题,并通过贝叶斯统计量化为达到MCID需要的后验概率。特别是本研究重新定义了功效偏倚,它不仅是试验人员需要考虑的一个基本问题,也是临床医生在解释循证证据时需要衡量的因素。
为选择那些对科研方向、未来试验设计以及临床实践最有影响力的试验,本研究只纳入了7大高影响力期刊发表的多中心 RCTs。低影响力期刊发表的小型试验通常对荟萃分析影响较大,明确这些试验是否普遍存在功效偏倚也很重要。为了便于试验间的比较,本研究只纳入了以病死率为主要终点的试验。 本研究并未将纳入试验局限于ICU内,而是包含了广义上的重症成人患者,这可能会增加试验间的异质性。
本研究未探讨包括预后型和预测型富集在内的其他改进试验设计的策略。
本研究在分析所有研究时,预设MCID绝对风险差为5%,相对风险差为 20%。但 MCID 可能取决于干预相关的风险情况以及幸存者的长期发病率。在患者个体角度而言,很难用病死率去定义MCID。本研究从临床角度出发,将 MCID 定义为足以改变临床实践的效应大小,类似于肿瘤试验中专业协会提出的定义[57]。据我们所知,重症疾病研究中尚无验证过的病死率 MCID。
为达到MCID,需要采用无信息先验分布建模确定贝叶斯后验概率。因此,类似于频率分析,后验概率将完全取决于试验数据;但是实际操作时,试验报告的贝叶斯结果会可能含有来自初始数据的先验信息分布结果。
结论
大多数重症多中心RCTs 都会高估对照组病死率,对预期疗效过于乐观,从而使试验结果偏向无效。功效偏倚使得试验很少得出微小但临床有重要疗效的肯定结论。结合 MCID 评估试验结果可以帮助临床解释。未来的试验可以考虑自适应设计,这可能会减少对功效和样本量错误估计带来的影响。
致谢
We thank Dr. B. Taylor Thompson, Massachusetts General Hospital, for his thoughtful feedback on the draft article. We also thank Dr. Quixuan Chen, Columbia University Mail-man School of Public Health, for her expert guidance with the Bayesian analysis.
Dr. Beitler involved in concept anddesign and statistical analysis. Drs. Abrams and Beitler involved in drafting of the article and supervision. All
authors involved in acquisition, analysis, or interpretation of data and crit-ical revision of the article for important intellectual content.
Supplemental digital content is available for this article. Direct URL cita-tions appear in the printed text and are provided in the HTML and PDF versions of this article on the journal's website (http://journals.Iww.com/ccmjournal).
Supported, in part, by grant from U.S. National Heart, Lung, and Blood Institute(K23-HL133489,R21-HL145506).
Dr. Montesi has received research funding through her institution from Merck, United Therapeutics, and Promedior outside the scope of this work, royalties from Wolters Kluwer for contributions to UpToDate, and she supported by grants from the Francis Family Foundation, the Scle-roderma Foundation, and the U.S. INational Institutes of Health (NIH). Dr. Brodie's institution received funding from ALung Technologies, Baxter, Xenios,Breethe,and Hemovent.Dr.Beitler's institution received funding from National Heart, Lung, and Blood Institute; he received funding from Hamilton Medical and consulting fees from Sedana Medical outside the scope of this work; and he received support for article research from NIH. The remaining authors have disclosed that they do not have any potential conflicts of interest.
For information regarding this article,E-mail:jrb2266@cumc.columbia.edu
参考文献
1. Significance of significant. N Eng/ J Med 1968; 278:1232-1233 2. Pocock SJ, Stone GW: The primary outcome fails-what next? N Engl J Med2016;375:861-870
3. Greenland S: Nonsignificance plus high power does not imply support for the null over the alternative. Ann Epidemio/2012;22:364-368
4. Calfee CS, Delucchi K, Parsons PE, et al; NHLBI ARDS Network:Subphenotypes in acute respiratory distress syndrome; Latent class analysis of data from two randomised controlled trials. Lancet Respir Med 2014;2:611-620
5. Seymour CW, Kennedy JN, Wang S, et al: Derivation, validation,and potential treatment implications of novel clinical phenotypes for sepsis. JAMA 2019;321:2003-2017
6. Adrie C, Adib-Conquy M, Laurent I, et al: Successful cardiopulmonary resuscitation after cardiac arrest asa“sepsis-like”syndrome.Circula-tion 2002;106:562-568
7.Reynolds HR,Hochman JS:Cardiogenic shock:Current concepts and improving outcomes. Circulation 2008;117:686-697
8. Garland A, Shaman Z, Baron J, et al: Physician-attributable differ-ences in intensive care unit costs: A single-center study. Am J Respir Crit Care Med 2006;174:1206-1210
9.Bellani G,Laffey JG,Pham T,et al;LUNG SAFE Investigators;ESICM Trials Group:Epidemiology,patterrs of care, and mortality for patients with acute respiratory distress syndrome in intensive care units in 50 countries.JAMA2016;315:788-800
10. Stevenson EK, Rubenstein AR, Radin GT, et al: Two decades of mor-tality trends among patients with severe sepsis: A comparative meta-analysis*.Crit Care Med 2014;42:625-631
11.du Bois RM, Weycker D, AlberaC,et al:Six-minute-walk test in idio-pathic pulmonary fibrosis: Test validation and minimal clinically impor-tant difference. Am J Respir Crit Care Med 2011;183:1237
12. Harhay MO, Wagner J, Ratcliffe SJ, et al: Outcomes and statistical power in adult critical care randomized trials. Am J Respir Crit Care Med 2014189:1469-1478
13. Aberegg SK, Richards DR, O'Brien JM: Delta inflation: A bias in the design of randomized controlled trials in critical care medicine. Crit Care2010;14:R77
14.Kim WB,Worley B,Holmes J, et al: Minimal clinically important dif-ferences for measures of treatment efficacy in Stevens-Johnson syn-drome and toxic epidermal necrolysis. J Am Acad Dermato/2018;79:1150-1152
15. Chapman M, Peake SL, Bellomo R, et al; Target Investigators,ANZICS Clinical Trials Group: Energy-dense versus routine enteral nutrition in the critically ill. N Eng/J Med 2018; 379:1823-1834
16. TARGET Investigators, Australian and New Zealand Intensive Care Society Clinical Trials Group: Statistical analysis plan for the aug-tested versus routine approach to giving energy trial (TARGET). Crit Care Resusc 2018;20:15-21
17. Ridgeon EE, Bellomo R, Aberegg SK, et al: Effect sizes in ongoing randomized controlled critical care trials. Crit Care 2017;21:132
18. Kaul S, Diamond GA: Trial and error. How to avoid commonly encoun-tered limitations of published clinical trials. JAm Coll Cardiol 2010;55:415-427
19. Brunkhorst FM, Engel C, Bloos F, et al; German Competence Net-work Sepsis (SepNet): Intensive insulin therapy and pentastarch re suscitation in severe sepsis. N Eng/J Med 2008; 358:125-139
20. Caironi P, Tognoni G, Masson S, et al; ALBIOS Study Investigators:Albumin replacement in patients with severe sepsis or septic shock. NEng/JMed2014;370:1412-1421
21. Cavalcanti AB, Suzumura EA et al; Writing Group for the Alveolar Recruitment for Acute Respiratory Distress Syndrome Trial Investiga-tors: Effect of lung recruitment and titrated positive end-expiratory pressure(PEEP) vs low PEEP on mortality in patients with acute res-piratory distress syndrome: A randomized clinical trial. JAMA 2017;318:1335-1345
22. De Backer D, Biston P, Devriendt J, et al; SOAP II Investigators: Com-parison of dopamine and norepinephrine in the treatment of shock. N Engl JMed 2010362:779-789
23. Holcomb JB, Tilley BC, Baraniuk S, et al; PROPPR Study Group;Transfusion of plasma, platelets, and red blood cells in a 1:1 vs a 1:1:2 ratio and mortality in patients with severe trauma: The PROPPR randomized clinical trial. JAMA 2015; 313:471-482
24.Ranieri VM, Thompson BT, Barie PS, et al; PROWESS-SHOCK Study Group: Drotrecogin alfa(activated) in adults with septic shock. NEng/JMed2012;366:2055-2064
25.Guerin C,Reignier J,Richard JC,et al;PROSEVA Study Group:Prone positioning in severe acute respiratory distress syndrome. N Eng/JMed2013;368:2159-2168
26. Combes A, Hajage D, Capellier G, et al; EOLIA Trial Group, REVA,and ECMONet: Extracorporeal membrane oxygenation for severe acute respiratory distress syndrome. NEng/ J Med 2018; 378:1965-1975
27. Guntupalli K, Dean N, Morris PE, et al; TLF LF-0801 Investigator Group: A phase 2 randomized, double-blind, placebo-controlled study of the safety and efficacy of taalactoferrin in patients with severe sepsis.Crit Care Med 2013;41:706-716
28.Zhang Q,Li C,Shao F,et al:Efficacy and safety of combination therapy of shenfu injection and postresuscitation bundle in patients with return of spontaneous circulation after in-hospital cardiac arrest:A randomized, assessor-blinded, controlled trial. Crit Care Med 2017;45:1587-1595
29. Karnad DR, Bhadade R, Verma PK, et al: Intravenous administration of ulinastatin (human urinary trypsin inhibitor) in severe sepsis: A multicenter randomized controlled study. Intensive Care Med 2014;40:830-838
30. van den Berghe G, Wouters P, Weekers F, et al: Intensive insulin therapy in critically ill patients. N EngI J Med 2001; 345:1359-1367
31. Finfer S, Chittock DR, Su SY, et al; NICE-SUGAR Study Investi-gators: Intensive versus conventiconal glucose control in critically ill patients.NEng/JMed2009;360:1283-1297
32.Rivers E,Nguyen B,Havstad S,et al;Early Goal-Directed Therapy Collaborative Group: Early goal-directed therapy in the treatment of severe sepsis and septic shock. N Eng/ J Med 2001; 345:1368-1377
33.Yealy DM,Kellum JA et al;ProCESS Investigators:A randomized trial of protocol-based care for early septic shock. N Engl J Med 2014;370:1683-1693
34. Anthon CT, Granholm A, Perner A, et al: Overall bias and sample sizes were unchanged in ICU trials over time: A meta-epidemiological study. JClin Epidemiol 2019; 113:189-199
35.Higgins JPT, Green S (Eds): Cochrane Handbook for Systematic Reviews of Interventions, Version 5.1.0.2011. Available at: http://handbook-5-1.cochrane.org. Accessed December 2,2019
36. Hochman JS: Cardiogenic shock complicating acute myocardial infarction: Expanding the paradigm. Circulation 2003; 107:2998-3002
37. Grissom CK, Hirshberg EL, Dickerson JB, et al; National Heart Lung and Blood Institute Acute Respiratory Distress Syndrome Clinical Tri-als Network: Fluid management with a simplified conservative pro-tocol for the acute respiratory distress syndrome*. Crit Care Med 201543:288-295
38. Chalmers I, Matthews R: What are the implications of optimism bias in clinical research? Lancet 2006; 367:449-450
39.Mann H, Djulbegovic B: Choosing a control intervention for a ran-domised clinical trial. BMC Med Res Methodol 2003; 3:7
40. Chan AW, Hrobjartsson A, Haahr MT, et al: Empirical evidence for selective reporting of outcomes in randomized trials: Comparison of protocols to published articles. JAMA 2004;291:2457-2465
41. Bassler D, Briel M, Montori VM, et al; STOPIT-2 Study Group: Stop-ping randomized trials early for benefit and estimation of treatment effects: Systematic review and meta-regression analysis. JAMA 2010;303:1180-1187
42. loannidis JP: Contradicted and initially stronger effects in highly citedclinical research. JAMA 2005; 294:218-228
43.de Grooth HJ,Parienti JJ,Postema J, et al: Positive outcomes, mor-tality rates, and publication bias inseptic shock trials. Intensive Care Med2018;44:1584-1585
44. Spragg RG, Bernard GR, Checkley W, et al: Beyond mortality: Fu-ture clinical research in acute lung injury. Am J Respir Crit Care Med 2010;181:1121-1127
45. Ospina-Tascon GA, Buchele GL,Vincent JL: Multicenter, randomized,controlled trials evaluating mortality in intensive care: Doomed to fail?Crit Care Med 2008;36:1311-1322
46. Bekaert M, Timsit JF, Vansteelandt S, et al; Outcomerea Study Group:Attributable mortality of ventilator-associated pneumonia: A reappraisal using causal analysis. Am J Respir Crit Care Med 2011;184:1133-1139
47. Shankar-Hari M, Harrison DA, Rowan KM, et al: Estimating attribut-able fraction of mortality from sepsis to inform clinical trials. J Crit Care 2018; 45:33-39
48. Girbes ARJ, de Grooth HJ: Time to stop randomized and large prag-matic trials for intensive care medicine syndromes: The case of sepsis and acute respiratory distress syndrome. J Thorac Dis 2020;12:S101-S109
49.Elsaßer A,Regnstrom J,Vetter T,et al∶ Adaptive clinical trial designs for European marketing authorization: A survey of scientific advice letters from the European Medicines Agency. Trials 2014;15:383
50.Bhatt DL,Mehta C:Adaptive designs for clinical trials. N Eng/ J Med 2016;375:65-74
51.van der Graaf R,Roes KC,vanDelden JJ: Adaptive trials in clinical research: Scientific and ethical issues to consider. JAMA 2012;307:2379-2380
52. Sterne JA, Davey Smith G: Sifting the evidence-what's wrong with significance tests? BMJ2001;322:226-231
53. Gardner MJ, Altman DG: Confidence intervals rather than P values: Estimation rather than hypothesis testing. Br Med J (Clin Res Ed)1986292746-750
54. Sackett DL: The principles behind the tactics of performing thera-peutic trials. In: Clinical Epiidemiology: How to Do Clinical Practice Research. Haynes RB, Sackett DL, Guyatt GH (Eds). Philadelphia, PA,Lippincott Williams&Wilkins,2006,pp 173-243
55. Diamond GA, Kaul S: Prior convictions: Bayesian approaches to the analysis and interpretation of clinical megatrials. J Am Coll Cardiol 2004;43:1929-1939
56. Lewis RJ, Angus DC: Time for clinicians to embrace their inner Bayesian: Reanalysis of results of a clinical trial of extracorporeal membrane oxygenation. JAMA 2018; 320:2208-2210
57.Ellis LM,Bernstein DS,Voest EE,et al: American Society of Clinical Oncology perspective: Raising the bar for clinical trials by defining clinically meaningful outcomes. J Clin Oncol 2014; 32:1277-1280
58. Moher D, Dulberg CS, Wells GA: Statistical power, sample size,and their reporting in randomized controlled trials. JAMA 194; 272:122-124
专家述评
杜 斌 中国医学科学院北京协和医院
对于重症医学而言,前瞻随机对照试验(RCT)得到阴性结果似乎是难以避免的命运。Abrams 等人总结了2008年至2018年间发表在高影响因子杂志的 101 项重症医学RCT发现,89项得到阴性结果。
RCT得到阴性结果的原因可能是多方面的。例如,研究假设可能存在问题,包括选择了错误的研究对象、干预时机及评价指标等。同时,方法学方面也可能存在问题,包括高估疗效、对照组的选择等。
本文作者发现,入选的101项RCT在预估样本量时,对照组绝对病死率平均高估6.7%;77.3% (75/97)的研究存在高估对照组病死率的现象。基于这样的假设,入选研究的样本量允许检测到的两组患者绝对病死率差异为9.0%,相对病死率差异为23%;而实际观察到的病死率差异中位数仅为 -0.2%。高估对照组病死率造成的后果之一,即,14项研究中干预措施需要避免半数的死亡才能达到假设疗效;其中2项研究中,即便干预措施避免所有死亡,也无法达到假设的绝对风险降低。
其实,这项研究从高估对照组病死率的角度再次说明了一个问题,过于乐观的估计(高估)干预措施的疗效,可能是造成 RCT阴性结果的重要原因。例如,本研究中近半数 RCT 在预估样本量时,预计绝对病死率降低为 10%。但是,实际结果发现, 仅有5项RCT可以达到这一目标。
因此,如何避免高估干预措施疗效,对于预估适宜的样本量至关重要。一方面,要详细评估入选患者与既往研究报告患者临床特征的差异,以更加准确地预测对照组病死率;另一方面,要求疗效预测应当超过所谓具有临床意义的最小差异(MCID),似乎也是避免样本量不足的手段。有趣的是,作为临床医生,我们是否能够对所有或多数不良事件都能够确定 MCID(例如,病死率至少下降几个百分点,住院日至少缩短几天,SOFA 评分至少降低几分,能够认定为具有意义),恐怕又是一个难以回答的问题。
祝媛 / 彭志勇 武汉大学中南医院
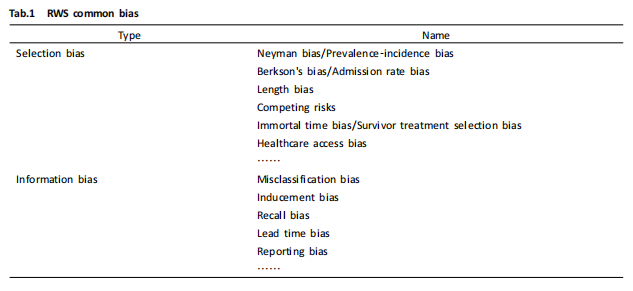
偏倚是导致研究结果偏离真值的现象,存在于临床试验选择和分配研究对象、实施干预措施、随访研究对象、测量和报告研究结果的每个阶段[1]。医学研究中最常用的随机对照试验(randomized control trail,RCT)的偏倚来源多样。根据研究阶段,偏倚可以主要分为选择偏倚、实施偏倚、随访偏倚、测量偏倚和报告偏倚[1]。但在临床实际进行的 RCTs 中,还存在其他影响试验检验效能和试验结果的潜在偏倚。
我国有关RCT的质量评价相对较少。为评估我国RCT质量,许多学者都对国内的 RCT 做了质量调查。研究显示约1.1%~4.4% 的中医 RCT 报告了样本量计算,而仅0.3%~4.9% 的 RCT 报告了分配隐藏方法[2,3]。这反映了国内 RCT 的报告质量亟待提高。临床研究质量的高低会影响对试验疗效的评估。低质量研究通常会使得疗效被高估。与高质量研究相比,低质量研究会导致平均疗效被高估 34%;而我国 RCT 常见的不报道分配隐藏的情况,会使得平均疗效被高估 37%[4]。临床试验中偏倚大小,同样会影响对疗效大小的评估。当偏倚较大时,试验结果倾向于高估疗效,从而使得临床重要治疗的真实疗效被掩盖[5]。
在重症医学领域,其疾病的复杂性和治疗手段的多元化使得研究对象间不可避免会存在差异,并增加了偏倚。Abrams D等人对重症医学RCTs中的功效偏倚和疗效进行了评估[6],他们采用马尔科夫链蒙特卡罗的贝叶斯模型来计算各项试验的后验概率,发现重症医学 RCT 中对照组死亡率预测值普遍较高,同时对预期疗效过于乐观,导致试验结果偏向无效。这种偏倚使得试验无法得 出微小但对临床有重要意义的肯定性结论。因此部分 RCT 得出的“阴性”结论,可能是各种偏倚掩盖了真实疗效的结果。
目前有关重症医学RCTs的质量评价研究较少。Abrams D等人建议结合最小临床意义变化值来解释试验结果,在今后的试验设计中也推荐使用自适应设计以期减少因功效和样本量错误估计带来的影响[6]。由于重症患者疾病的特异性,对今后的重症医学RCTs应当要求对其试验设计进行更严格的审查,并要求详细说明其应报告的方法学内容[7]。总之,应当从临床试验的各个阶段出 发减少偏倚,从而使试验能尽可能地反映研究人群中的真实疗效。
参考文献
1. 王家良,邸阜生,田文静等 . 循证医学 [M]. 第 3 版 . 北京 : 人民卫生出版社 , 2016.
2. WANG GANG, MAO BING, XIONG ZE-YU,et al. The quality of reporting of randomized controlled trials of traditional Chinese medicine: a survey of 13 randomly selected journals from mainland China [J]. Clin Ther, 2007, 29(7): 1456-67.
3. 于丹丹,谢雁鸣,廖星等 . 《中国中药杂志》发表随机对照试验方法学和报告质量评价研究 [J]. 中国中药杂志 , 2018, 43(04): 833-9.
4. MOHER D., PHAM B., JONES A.,et al. Does quality of reports of randomised trials affect estimates of intervention efficacy reported in meta-analyses? [J]. Lancet, 1998, 352(9128): 609-13.
5. HARTLING LISA, OSPINA MARIA, LIANG YUANYUAN,et al. Risk of bias versus quality assessment of randomised controlled trials: cross sectional study [J]. BMJ, 2009, 339: b4012.
6. ABRAMS DARRYL, MONTESI SYDNEY B., MOORE SARAH K. L.,et al. Powering Bias and Clinically Important Treatment Effects in Randomized Trials of Critical Illness [J]. Crit Care Med, 2020, 48(12): 1710-9.
7. COOK DAVID J., RUTHERFORD WILLIAM B., SCALES DAMON C.,et al. Rationale, Methodological Quality, and Reporting of Cluster-Randomized Controlled Trials in Critical Care Medicine: A Systematic Review [J]. Crit Care Med, 2021.
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言









#重症医学##随机试验#中的功效#偏倚#和临床重要疗效,这个非常重要!在#研究设计#时务必重视,才能做出高质成果
71