
【佳作推荐】京都大学Y. Okuno团队JCIM论文:利用自训练方法准确预测药物-靶标相互作用
2023-09-15 ComputArt计算有乐趣 ComputArt计算有乐趣 发表于上海

京都大学的Y. Okuno团队提出了一种自训练方法进行数据增强并获得了一个泛化能力强的药物-靶标相互作用预测模型。
识别药物和靶标之间是否具有相互作用是早期药物发现中的关键环节。相比于耗时费力的实验方法,使用计算方法预测药靶关系已经成为主流。用于识别药靶相互作用的计算方法可以按是否依赖于蛋白质结构而粗略地分为两类,其中基于结构的方法不需要药靶关系的先验知识,对打分函数的精度和结合模式的质量有很高的要求,另一种方法根据已探明的药靶作用进行推测,包括基于网络推理的方法和基于矩阵分解的方法等。
近年来,以ChEMBL、PDBbind等为代表的公开数据集发展迅速,可得的药靶关系数据越来越多,不依赖结构的预测方法迎来了发展契机。不过,由于这类方法极其依赖先验数据的质量,数据巨大、难以质控的数据也常常成为这些预测方法的桎梏。目前公开数据中经过实验验证的非活性数据是稀缺的,不平衡的数据常常导致较差的预测泛化能力。
为了解决上述问题,研究人员常常采用随机配对产生新非活性样本,这却可能产生假阴性的数据而误导模型的决策。因此,京都大学的Y. Okuno团队提出了一种自训练方法进行数据增强并获得了一个泛化能力强的药物-靶标相互作用预测模型。相关工作近期发表在美国化学会出版的计算化学与化学信息学核心期刊Journal of chemical information and modeling上(J. Chem. Inf. Model. 2023, 63, 15, 4552–4559)。
本文中,研究者从ChEMBL、BioPrint、Davis和BindingDB四个数据库中广泛收集了实验验证的蛋白-配体相互作用数据,并通过随机配对的方式产生了无标签样本,模型则采用经典的自训练方法构建。自训练方法主要有两部分组成:教师模型和学生模型。教师模型首先在有标签的数据集上进行训练,然后对无标签模型进行预测,以预测值作为“软标签”加入训练集供学生模型训练,训练完成的学生模型又可以作为教师模型为新的学生模型提供新的“软标签”。迭代多轮后,我们就可以得到一个覆盖较大样本空间的模型。
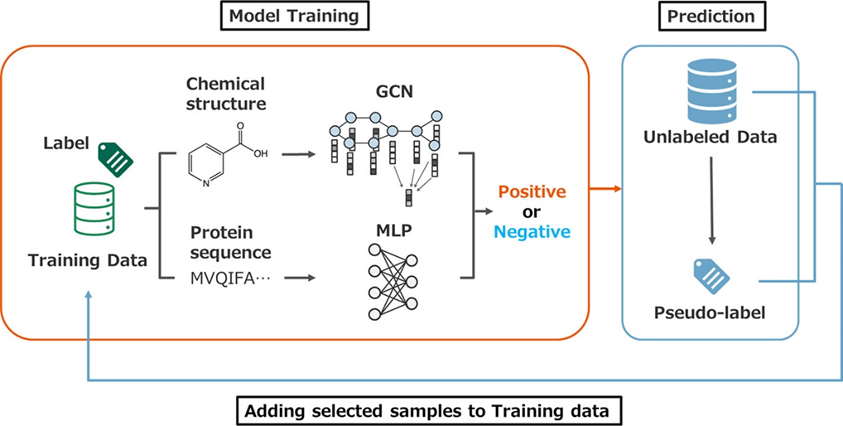
图1:自训练方法的流程及模型主要架构示意图
在模型性能评价阶段,研究者分别在内部和外部测试集上都进行了测试。相比于基准模型,使用了自训练进行数据扩增的模型在G蛋白偶联受体和激酶两大类蛋白上平均ROC-AUC(受试者工作特征曲线下面积)和PR-AUC(精度-召回曲线下面积)分别从0.9139和0.9962提高到0.9336和0.9974,与其他试图解决数据不平衡问题的方法比也有明显的指标领先。在BioPrint、Davis和BindingDB这三个外部测试集上,自训练模型相比于基准模型在两个指标上也各有小幅度提升。值得注意的是,尽管自训练增加了非活性样本以平衡数据集,但模型并没有倾向于给出非活性的预测结果。然后研究者以Davis数据集在蛋白水平评估了模型的泛化能力。与其他方法获得的模型相比,自训练模型在测试集中新靶标上能够取得更高的指标,说明自训练策略能帮助模型将有效的决策边界推广到了训练集之外。
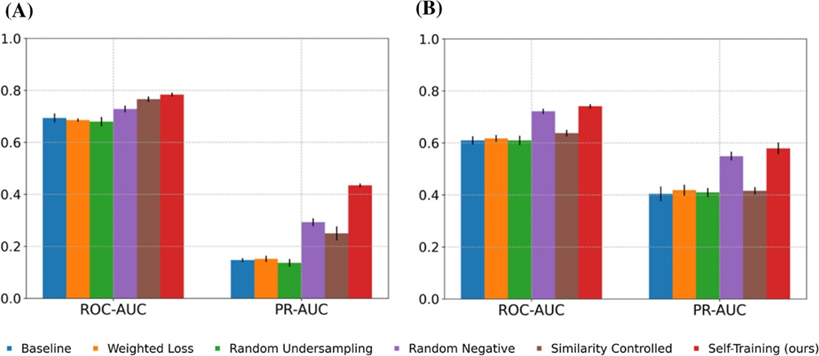
图2:各类模型在外部测试集上的性能。(A)在BioPrint数据集上的测试结果;(B)在Davis数据集上的测试结果
最后,研究者对训练集中的活性和非活性样本进行可视化以验证方法的有效性。如图3所示,自训练得到的模型本就能够获得更清晰的决策边界,而增加“软标签”标记的数据后(图3C),原数据的分布没有被破坏且决策边界更加明显,充分证明了其方法的优势。
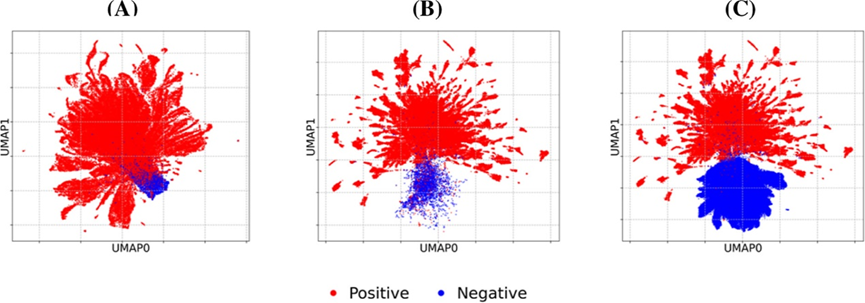
图3:使用UMAP对训练集中的激酶类样本进行可视化展示。(A)基准模型;(B)自训练模型;(C)增加“软标签”样本的自训练模型
小编评论
该文作者开发了一个基于自训练进行数据增强的药物-靶标相互作用预测模型,是一个使用自训练的半监督学习典型案例,但小编认为其创新之处稍显不足。作为一种比较先进的训练方法,该工作的结果领先一些“传统”方法似乎是理所应当的,缺少必要的和其它先进方法比较的结果。另外,该工作虽然广泛收集了公开数据集中的药靶关系并制作了训练集和测试集,数据量上有明显的提高,但是没有对训练集进行去冗余处理,这可能导致对模型性能的高估。总体而言,该工作为我们展示了数据量较少或数据集不平衡时如何提高模型的泛化能力,对相关药物研发人员具有启发价值。
参考文献
【1】Koyama, T.; Matsumoto, S.; Iwata, H.; Kojima, R.; Okuno, Y., Improving Compound-Protein Interaction Prediction by Self-Training with Augmenting Negative Samples. J. Chem. Inf. Model. 2023, 63, 4552-4559.
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言





很想学习
36