Cell:计宏凯/Reza Kalhor团队合作利用细胞谱系条形码重建定量化的细胞命运图谱
2022-11-24 “小柯生命” “小柯生命”公众号 发表于上海

该框架为未来该领域的实验设计建立了理论依据和分析工具,并在研究胚胎发育、细胞分化、肿瘤形成及其它相关问题中具有广泛的潜在用途。
2022年11月23日,美国约翰斯?霍普金斯大学Reza Kalhor团队与计宏凯团队合作在Cell杂志上以长文形式发表了题为“Quantitative fate mapping: A general framework for analyzing progenitor state dynamics via retrospective lineage barcoding” 的研究论文。
该研究创建了一套从DNA细胞谱系条形码(cell lineage barcode)回溯推测并量化建模细胞命运决定过程的理论和方法学框架。该框架为未来该领域的实验设计建立了理论依据和分析工具,并在研究胚胎发育、细胞分化、肿瘤形成及其它相关问题中具有广泛的潜在用途。

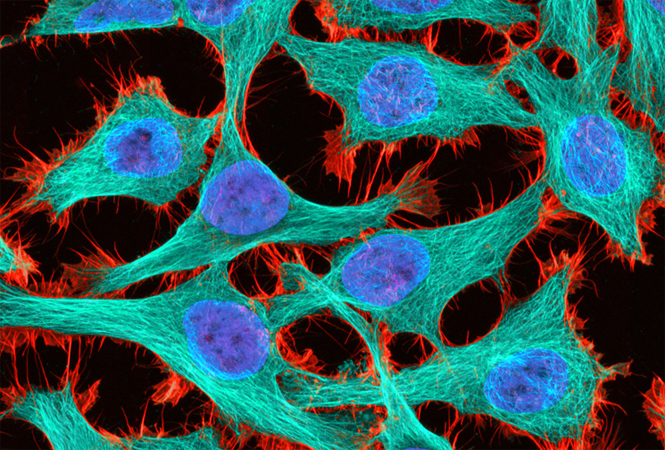
在细胞分裂时,DNA里随机发生的突变会被子细胞遗传,而子细胞中又会产生新的突变。经过这样的过程,最终每个细胞都会带上各自的突变指纹,也被称为“细胞谱系条形码”(cell lineage barcode)(图1)。

图1:小鼠发育中的细胞谱系条形码
这些谱系条形码可以是人工通过基因编辑引发的(例如现已在小鼠中被实现的MARC1以及斑马鱼等中被实现的scGESTALT),也可以是自然生成的(例如人体发育过程中及肿瘤中的体细胞突变)。在细胞演化的系统发生树(cell phylogeny)中,亲缘关系相近的细胞的谱系条形码会更为相似,而亲缘关系远的细胞的谱系条形码则会更不同。因此,直觉上细胞的演化关系可以通过分析一个生物样本中细胞的谱系条形码来反向推测。如果该方法可行,那么它将有很多潜在应用。例如生物在发育过程中,从一个全能的单细胞,通过一系列的命运决定逐渐失去其多能性,最终成为各种不同的细胞类型。其间,不同类型的祖细胞(progenitor cells)逐渐分裂,失去其多能性,并变得更加多样。对于这个过程的研究是发育生物学的核心课题。
对细胞谱系条形码的分析为回答这个问题提供了一种新的手段。传统的多时间点采样无法直接建立多个时间点细胞间的关系,而近来的单细胞拟时间(pseudotime)更适合在较短时间尺度上研究细胞动态变化。谱系条形码能够利用单个时间点的样本更好地在较长的时间尺度上反推细胞演化。因此,这一方法在研究时间跨度较长又不能重复采样(例如手术得到的肿瘤样本)的生物过程中具有其独特的优势。
然而,如何利用谱系条形码来描述细胞类型分化以及祖细胞命运决定这一随机过程,并不像直觉想象的那么简单。其中有很多悬而未决的理论问题尚没有一个清晰的答案。
首先,虽然谱系条形码能被用来重建细胞间演变关系的系统发生树,细胞的系统发生树却只描述单细胞之间的亲缘关系,即其分裂历史,而并不直接描述不同祖细胞类型和状态之间的关系。这是因为在高等生物中,并不是每一次细胞分裂都伴随命运决定与祖细胞状态的变化。在细胞类型上非常相近的细胞往往是不同的干细胞产生的,导致其在系统树上的距离可以非常远。而细胞类型不同的细胞有可能来自同一个干细胞,因而在系统树上的距离可以更近。这就好比张三家的兄妹和李四家的兄妹, 每家的兄妹之间亲缘关系更近(类似于条形码更相近),但是两家的哥哥却同属一个性别(类似于细胞类型相同)。这样同属一个性别的两个人(类似于同类型的两个细胞)在系统树上反而离得更远。所以,描述细胞亲缘关系的系统发生树和重构祖细胞类型的分化过程并不等价。
其次,单细胞经历命运决定的过程有其随机性,尽管相同的细胞类型在不同个体中总会出现,但每次发育所产生的系统发生树却可以非常不同。
最后,当前技术下,同时能够进行测序的单细胞数目仍然有限,从一个个体成百上千万的细胞中收集的有限的样本能够给出多少有用的信息也仍不清楚。另外,细胞系统树重建本身也有自身的难点。
由于以上原因,细胞谱系条形码能否以及如何被用来获取什么样的在生物与医学方面有意义的信息,领域内还缺乏相关的工作。例如,我们能不能通过细胞谱系条形码推测出不同类型祖细胞分化的时间和先后顺序?我们可不可以估计出分化前祖细胞的多少和不同子细胞类型的比例?

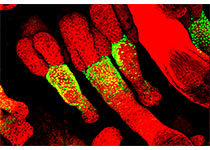
图2:利用谱系条形码重建定量化的细胞命运图谱
为了回答上述问题,该研究团队通过计算模拟以及体外实验系统地研究了如何使用细胞谱系条形码研究细胞类型演化和命运决定,并提出了一套新的计算方法来反向推测细胞类型分化的时间,顺序,祖细胞数目及分化比例,并以此重建“定量化的细胞命运图谱” (Quantitative fate map) (图2)。这一分析框架含有两个步骤。
第一步,Phylotime算法基于细胞谱系条形码重建有时间尺度的细胞系统发生树。此方法具有很强的扩展性,能被应用到有很多细胞的大样本上。
第二步,ICE-FASE算法基于有时间尺度的细胞系统发生树重建定量化的细胞命运图谱。
这一方法产生的定量化的细胞命运图谱可以用来描述生物发育过程中的一些重要参数,包括:
(1)各个祖细胞类型产生的时间顺序和等级结构,
(2)各个祖细胞类型发生命运决定的时间,
(3)各个祖细胞群的细胞数目,
(4)各个祖细胞类型命运决定时产生不同子细胞类型的比例。
在研究中,作者发现与祖细胞群相关的重建与参数估计的准确程度取决于所有祖细胞群中有多少的后代能在测序时被采样到。例如,假设人的前脑刚形成是一个两百个细胞的祖细胞群,而最终测序的终端子细胞如果只覆盖了这两百个细胞中的二十个,那么参数估计结果的可靠性将会很低。但是如果终端子细胞覆盖了这两百个细胞中的五十个,那么参数估计结果就会比较可靠。根据这些分析结果,作者提出了测序的细胞数目需要与祖细胞群细胞数目在同一个数量级的定性标准。而基于已有的实验结果,作者提出了“祖细胞群覆盖度”的统计量,用来对参数估计的准确程度做定量分析。
这一系列结果回答了什么条件下细胞的谱系条形码才能用来准确的重构并推测细胞类型演化和命运决定的过程这一基础问题,并提供了相应的计算分析方案。
综上所述,此研究建立了一个通过细胞谱系条形码研究复杂的细胞分化过程及其动态参数的理论框架,为未来该领域的实验设计建立了指导方向。
约翰斯霍普金斯大学生物统计系计宏凯教授和生物医学工程系Reza Kalhor教授为本文的共同通讯作者。计宏凯教授团队的博士生房玮翔(现Reza Kalhor实验室博士后)为本文的第一作者。
原始出处:
Weixiang Fang, et al. Quantitative fate mapping: A general framework for analyzing progenitor state dynamics via retrospective lineage barcoding. Cell, 2022.
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言