
用SPSS进行曲线回归分析实例
2010-12-18 MedSci原创 MedSci原创

曲线回归分析 在一元回归中,若因变量和自变量相关的趋势不是线性分布,呈现曲线关系。这种情况可以利用SPSS提供的曲线估计过程(Curve Estimation)方便地进行线性拟合,选出最佳的回归模型来拟合出相应曲线。 下面以一个实例来介绍曲线拟合的基本步骤和使用方法。 例子 台湾稻螟蚁螟侵入不同叶龄稻茎后的生存率数据(表4-1)。拟合出适合的曲线模型,来表达不同叶龄稻茎对台湾稻螟蚁螟侵入的
曲线回归分析
在一元回归中,若因变量和自变量相关的趋势不是线性分布,呈现曲线关系。这种情况可以利用SPSS提供的曲线估计过程(Curve Estimation)方便地进行线性拟合,选出最佳的回归模型来拟合出相应曲线。
下面以一个实例来介绍曲线拟合的基本步骤和使用方法。
例子
台湾稻螟蚁螟侵入不同叶龄稻茎后的生存率数据(表4-1)。拟合出适合的曲线模型,来表达不同叶龄稻茎对台湾稻螟蚁螟侵入的生存关系。
表4-1 台湾稻螟蚁螟侵入不同叶龄稻茎后的生存率数据
|
生存率 |
8.9 |
10.3 |
12.3 |
12.9 |
13.1 |
13.5 |
13.8 |
13.6 |
12.7 |
13.5 |
|
叶龄 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
本例子数据保存在DATA6-3.SAV。
1)准备分析数据
在SPSS数据编辑窗口建立变量“生存率”和“叶龄”两个变量,把表6-13中的数据输入到对应的变量中。
或者打开已经存在的数据文件(DATA6-3.SAV)。
2)启动线性回归过程
单击SPSS主菜单的“Analyze”下的“Regression”中“Curve Estimation”项,将打开如图4-1所示的线回归对话窗口。
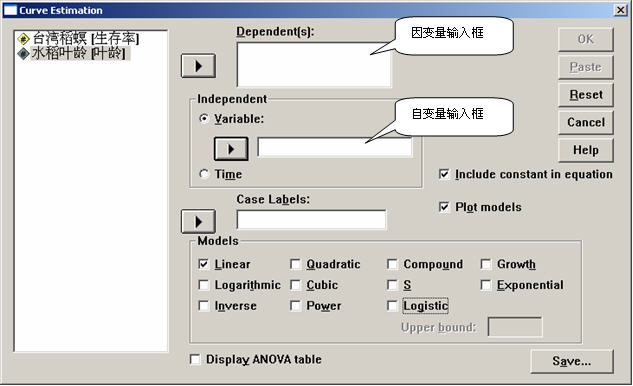
图4-1 线回归对话窗口
3) 设置分析变量
设置因变量:从左侧的变量列表框中选择一个或多个因变量进入“Dependent(s)”框。本例子选“生存率”变量为因变量。
设置自变量:选择一个变量为自变量,进入“Independent”框,也可选取“Independent”框中的“Time”项,即以时间为自变量。本例子选“叶龄”变量为自变量。
选择标签变量: 选择一个变量进入到“Case Labels”框中,该变量为标签变量,可以利用该变量的值在图上查找观测值。本例子没有标签变量。
4)选择曲线方程模型
在“Models”框中选择一个或多个回归方程模型,这11个模型都可化为相应的线性模型。其中各项的意义分别为:
(1) Linear 线性模型 ![]()
(2) Quadratic 二次模型 ![]()
(3) Compound 复合模型 ![]()
(4) Growth 生长模型 ![]()
(5) Logarithmic 对数模型 ![]()
(6) S 形模型 ![]()
(7) Cubic 抛物线模型 ![]()
(8) Exponential 指数的模型 ![]()
(9) Inverse 倒数模型 ![]()
(10) Power 幂函数模型 ![]()
(11) Logistic 逻辑斯蒂模型 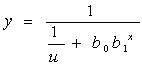
在各项模型上单击鼠标右键,可以得到模型的方程类型。当选中“Logistic”项时,应在“Upper bound”框中输入一个数值作为逻辑模型的上限值。
本例子选中第9号模型(Inverse,倒数模型)。
5)设置方程常数项
选中“Include constant in equation”项回归方程中包含常数项。
6)绘制模型拟合图
选中“Plot models”项绘制出回归方程模型图。本例子选中此项。
7)输出方差分析表
选中“Display ANOVA table”项,将输出方差分析表。
8) 保存分析数据
单击“Save”按钮,将打开如图4-2所示的对话框。该对话框用于选择要保存的新变量。

图4-2 曲线回归保存值设置对话窗口
“Save Variables”框中列出了可保存的新变量:
![]() “Predicted values”预测值。因变量的预测值。
“Predicted values”预测值。因变量的预测值。
![]() “Residuals”残差。因变量的观测值和预测值的差。
“Residuals”残差。因变量的观测值和预测值的差。
![]() “Prediction intervals”残差因变量的预测区间。
“Prediction intervals”残差因变量的预测区间。
当选中“Prediction intervals”项时,可在该项下面的“Confidence interval”框中输入显著性水平。
本例子选中“Predicted values”项、“Residuals”项和“Prediction intervals”项。
“Predict cases”:当选择时间序列为自变量时,本栏设置一个超过数据时间序列的预测周期。其中各项的意义分别为:
![]() “Predict from estimation period through last case”根据估计周期为所有的观测量提供预测周期。
“Predict from estimation period through last case”根据估计周期为所有的观测量提供预测周期。
![]() “Predict through”当要预测的观测量超过当前的数据时间序列时,输入观测量的一个周期数值。
“Predict through”当要预测的观测量超过当前的数据时间序列时,输入观测量的一个周期数值。
9)提交执行
在主对话框里单击“OK”,提交执行,结果将显示在输出窗口中。输出结果主要分两部分:第一部分是文本输出,给出了曲线模型、各统计量、方差分析以及曲线方程系数,见图3-3;第二部分是预测模型与分析数据的图形比较,见图3-2。
有时SPSS在输出浏览窗口不会完全显示出来所有的文本,在文本框左下角显示了一个红色三角形来提示我们。可以使用鼠标选中文本块,拖动鼠标把文本框扩大,直至显示出全部文本。
根据“曲线回归保存值设置对话窗口”的设置,SPSS在数据编辑窗口增添如下变量:
- fit_1为线性预测值;
- err_1为观测值和线性预测值的差值;
- lcl_1和ucl_1分别为显著性水平为95%的线性预测区间的上限和下限。
10) 结果分析
主要结果:

图3-3 曲线回归的文字输出部分

图3-4 回归方程模型图
分析:
建立回归模型:
根据图3-3中方程变量表得:
y = 14.861706 - 11.890356/x
回归方程的显著性检验:
回归方程的方差分析表明:F=81.94,显著水平为0.000。相关系数平方(R2)=0.91105。
从图3-4回归方程模型图中也可以看出模型拟合程度是很好的。
结果: 表明用“ y = 14.861706 - 11.890356/x”模型能很好地描述了水稻不同叶龄(x)对台湾稻螟蚁螟侵入后生存率(y)影响的数量相关关系。
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言




#回归分析#
35