在python中使用KNN算法处理数据中的缺失值
2020-10-31 Dario Radečić deephub翻译组

处理缺失的数据并不是一件容易的事。 方法的范围从简单的均值插补和观察值的完全删除到像MICE这样的更高级的技术。 解决问题的挑战性是选择使用哪种方法。 今天,我们将探索一种简单但高效的填补缺失数据的方
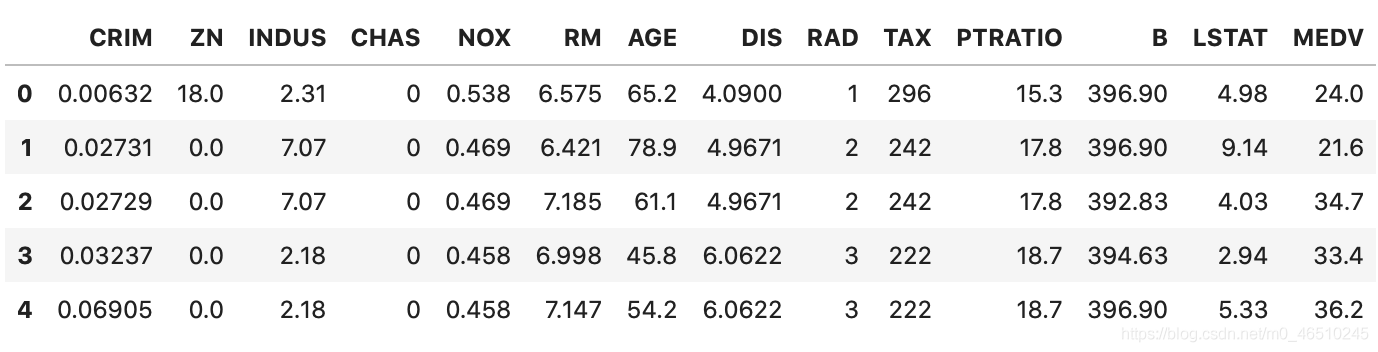
处理缺失的数据并不是一件容易的事。 方法的范围从简单的均值插补和观察值的完全删除到像MICE这样的更高级的技术。 解决问题的挑战性是选择使用哪种方法。 今天,我们将探索一种简单但高效的填补缺失数据的方法-KNN算法。 KNN代表“ K最近邻居”,这是一种简单算法,可根据定义的最接近邻居数进行预测。 它计算从您要分类的实例到训练集中其他所有实例的距离。 正如标题所示,我们不会将算法用于分类目的,而是填充缺失值。 本文将使用房屋价格数据集,这是一个简单而著名的数据集,仅包含500多个条目。 这篇文章的结构如下: 数据集加载和探索 KNN归因 归因优化 结论 数据集加载和探索 如前所述,首先下载房屋数据集。 另外,请确保同时导入了Numpy和Pandas。 这是前几行的外观: 默认情况下,数据集缺失值非常低-单个属性中只有五个: 让我们改变一下。 您通常不会这样做,但是我们需要更多缺少的值。 首先,我们创建两个随机数数组,其范围从1到数据集的长度。 第一个数组包含35个元素,第二个数组包含20个(任意选择): i1 = np.random.choice(a=df.index, size=35
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言





#缺失值#处理方法
93