那些年,收到的让人无法回答的审稿人意见
2020-03-16 小白学统计 小白学统计

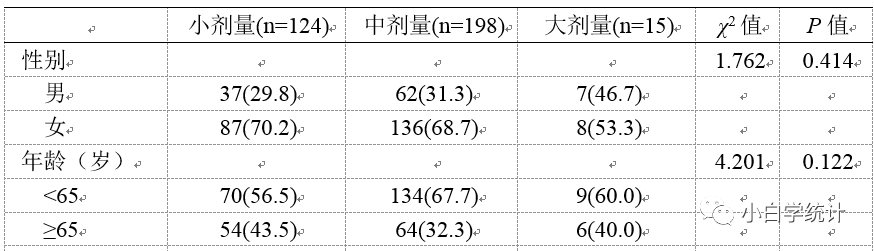
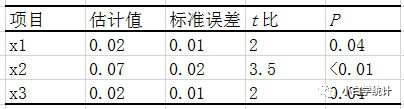
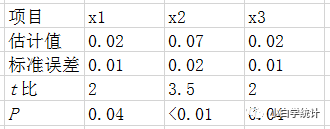
写文章投稿,审稿人给出的建议是五花八门。林子大了,什么鸟都有。同样,审稿意见多了,什么内容都有。虽然我们尊重审稿人及其意见,然而,总有一些审稿意见让人真的无法回答,又难以反驳。本文聊一下我个人遇到的一

本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言










学习
88
#审稿#
38