

前两篇文章中,小编向大家介绍了真实世界研究中的混杂因素及其常用的校正方法,特别是倾向性评分匹配和逆概率加权,以及SAS中的实现。这篇文章我们重点介绍在R中的实现。
还是先回顾一下数据背景。我们用的数据来源是荷兰格罗宁根市肾脏和血管终末期疾病预防(PREVEND)的队列研究(Joosten, 2014)。
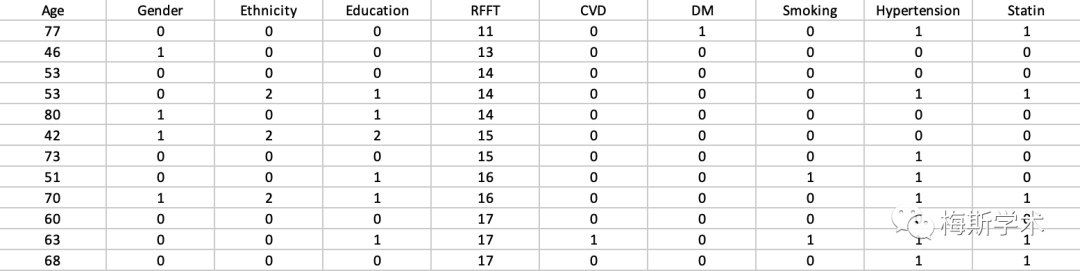
图1. 原数据部分截图

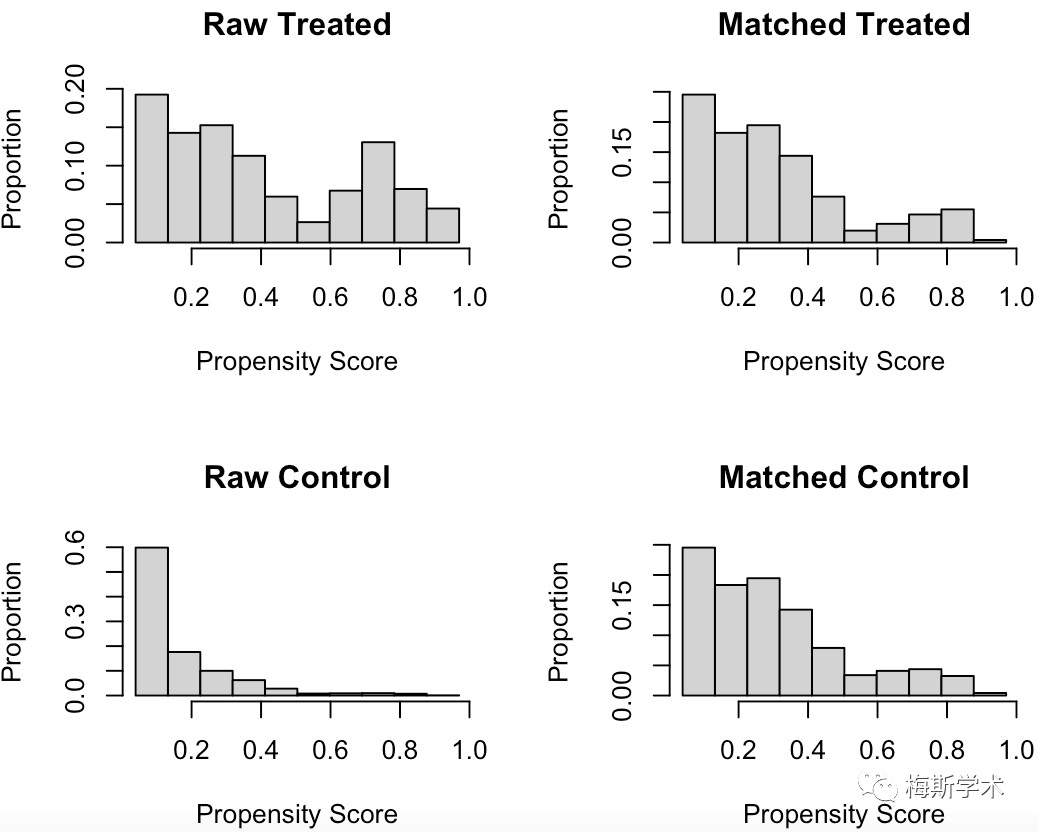
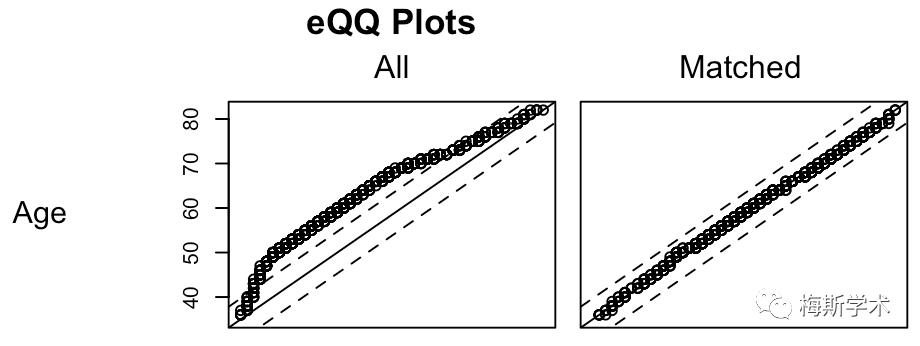
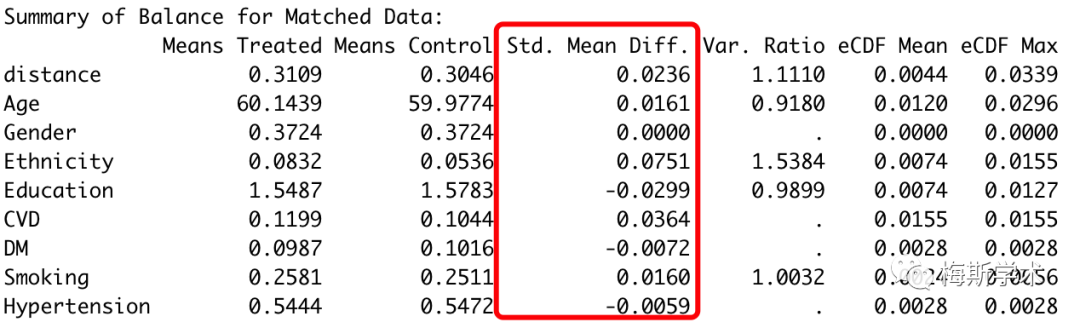
-
ipwpoint: 用于”point treatment situation”,即混杂因素和我们想探究的结果(outcome)是静态的; -
ipwtm: 用于随时间变化的自变量和混杂因素; -
tstartfun: 用于计算基线到随访各个阶段的时间,通常和Cox风险回归结合起来用在生存性分析研究中。

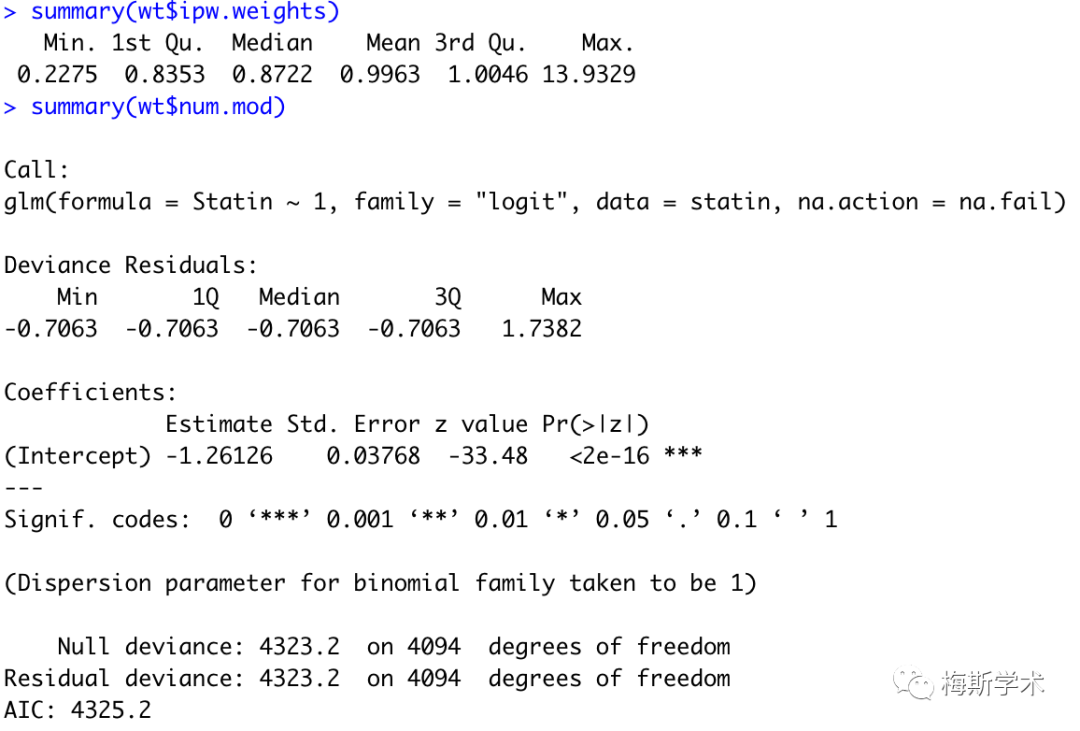


版权声明:
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言






