SPSS教程第十四课:非参数检验
2012-04-12 生物谷 生物谷

许多统计分析方法的应用对总体有特殊的要求,如t检验要求总体符合正态分布,F检验要求误差呈正态分布且各组方差整齐,等等。这些方法常用来估计或检验总体参数,统称为参数统计。 但许多调查或实验所得的科研数据,其总体分布未知或无法确定,这时做统计分析常常不是针对总体参数,而是针对总体的某些一般性假设(如总体分布),这类方法称非参数统计(Nonparam
许多统计分析方法的应用对总体有特殊的要求,如t检验要求总体符合正态分布,F检验要求误差呈正态分布且各组方差整齐,等等。这些方法常用来估计或检验总体参数,统称为参数统计。
但许多调查或实验所得的科研数据,其总体分布未知或无法确定,这时做统计分析常常不是针对总体参数,而是针对总体的某些一般性假设(如总体分布),这类方法称非参数统计(Nonparametric tests)。
非参数统计方法简便,适用性强,但检验效率较低,应用时应加以考虑。
第一节 Chi-Square过程
13.1.1 主要功能
调用此过程可对样本数据的分布进行卡方检验。卡方检验适用于配合度检验,主要用于分析实际频数与某理论频数是否相符。
13.1.2 实例操作
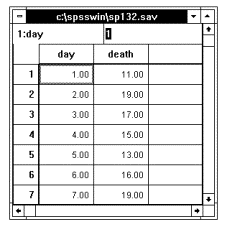
[例13-1]某地一周内各日死亡数的分布如下表,请检验一周内各日的死亡危险性是否相同?
|
周 日 |
死亡数 |
|
一 二 三 四 五 六 日 |
11 19 17 15 15 16 19 |
13.1.2.1 数据准备
激活数据管理窗口,定义变量名:各周日为day,死亡数为death。按顺序输入数据, 结果见图13.1。激活Data菜单选Weight Cases...命令项,弹出Weight Cases对话框(如图13.2),选death点击钮使之进入Frequency Variable框,定义死亡数为权数,再点击OK钮即可。

图13.1 数据录入窗口

图13.2 数据加权对话框
13.1.2.2 统计分析
激活Statistics菜单选Nonparametric Tests中的Chi-Square...命令项,弹出Chi-Square Test对话框(图13.3)。现欲对一周内各日的死亡数进行分布分析,故在对话框左侧的变量列表中选day,点击钮使之进入Test Variable List框,点击OK钮即可。

图13.3 卡方检验对话框
13.1.2.3 结果解释
在结果输出窗口中将看到如下统计数据:
运算结果显示一周内各日死亡的理论数(Expected)为15.71,即一周内各日死亡均数;还算出实际死亡数与理论死亡数的差值(Residual);卡方值χ2 = 3.4000,自由度数(D.F.)= 6 ,P = 0.7572 ,可认为一周内各日的死亡危险性是相同的。
|
DAY Cases Category Observed Expected Residual 1.00 11 15.71 -4.71 2.00 19 15.71 3.29 3.00 17 15.71 1.29 4.00 15 15.71 -.71 5.00 13 15.71 -2.71 6.00 16 15.71 .29 7.00 19 15.71 3.29 --- Total 110 Chi-Square D.F. Significance 3.4000 6 .7572 |
第二节 Binomial过程
13.2.1 主要功能
有些总体只能划分为两类,如医学中的生与死、患病的有与无。从这种二分类总体中抽取的所有可能结果,要么是对立分类中的这一类,要么是另一类,其频数分布称为二项分布。调用Binomial过程可对样本资料进行二项分布分析。
13.2.2 实例操作
[例13-2]某地某一时期内出生40名婴儿,其中女性12名(定Sex=0),男性28名(定Sex=1)。问这个地方出生婴儿的性比例与通常的男女性比例(总体概率约为0.5)是否不同?
13.2.2.1 数据准备
激活数据管理窗口,定义性别变量为sex。按出生顺序输入数据,男性为1 ,女性为0。
13.2.2.2 统计分析
激活Statistics菜单选Nonparametric Tests中的Binomial Test...命令项,弹出 Binomial Test对话框(图13.4)。在对话框左侧的变量列表中选sex,点击钮使之进入Test Variable List框,在Test Proportion框中键入0.50,再点击OK钮即可。

图13.4 二项分布检验对话框
13.2.2.3 结果解释
在结果输出窗口中将看到如下统计数据:
二项分布检验表明,女婴12名,男婴28名,观察概率为0.7000(即男婴占70%),检验概率为0.5000,二项分布检验的结果是双侧概率为0.0177,可认为男女比例的差异有高度显著性,即与通常0.5的性比例相比,该地男婴比女婴明显为多。
|
SEX Cases Test Prop. = .5000 28 = 1.00 Obs. Prop. = .7000 12 = .00 -- Z Approximation 40 Total 2-Tailed P = .0177 |
第三节 Runs过程
13.3.1 主要功能
依时间或其他顺序排列的有序数列中,具有相同的事件或符号的连续部分称为一个游程。调用Runs过程可进行游程检验,即用于检验序列中事件发生过程的随机性分析。
13.3.2 实例操作
[例13-3]某村发生一种地方病,其住户沿一条河排列,调查时对发病的住户标记为“1”,对非发病的住户标记为“0”,共17户:
|
0 1 1 0 0 0 1 0 0 1 0 0 0 0 1 1 0 0 1 0 0 0 0 1 0 1 |
问病户的分布排列是呈聚集趋势,还是随机分布?
13.3.2.1 数据准备
激活数据管理窗口,定义住户变量为epi。按住户顺序输入数据,发病的住户为1 ,非发病的住户为0。
13.3.2.2 统计分析
激活Statistics菜单选Nonparametric Tests中的Runs Test...项,弹出 Runs Test对话框(图13.5)。在对话框左侧的变量列表中选epi,点击钮使之进入Test Variable List框。在临界割点Cut Point框中有四个选项:

图13.5 游程检验对话框
2、Mode:众数作临界割点,其值在临界割点之下的为一类,大于或等于临界割点的为另一类;
3、Mean:均数作临界割点,其值在临界割点之下的为一类,大于或等于临界割点的为另一类;
4、Custom:用户指定临界割点,其值在临界割点之下的为一类,大于或等于临界割点的为另一类;
本例选Custom项,在其方框中键入1(根据需要选项,本例是0、1二分变量,故临界割点值用1),再点击OK钮即可。
13.3.2.3 结果解释
在结果输出窗口中将看到如下统计数据:
检验结果可见本例游程个数为14,检验临界割点值(Test value) = 1.00,小于1.00者有17个案例,而大于或等于1.00者有9个案例。Z = 0.3246,双侧 P = 0.7455。 所以认为此地方病的病户沿河分布的情况无聚集性,而是呈随机分布。
|
EPI Runs: 14 Test value = 1.00 Cases: 17 LT 1.00 9 GE 1.00 Z = .3246 -- 26 Total 2-Tailed P = .7455 |
第四节 1-Sample K-S过程
13.4.1 主要功能
调用此过程可对单样本进行Kolmogorov-Smirnov Z检验,它将一个变量的实际频数分布与正态分布(Normal)、均匀分布(Uniform)、泊松分布(Poisson)进行比较。
13.4.2 实例操作
[例13-4]某地正常成年男子144人红细胞计数(万/立方毫米)的频数资料如下,问该资料的频数是否呈正态分布?
|
红细胞计数 |
人数 |
红细胞计数 |
人数 |
|
420- 440- 460- 480- 500- 520- |
2 4 7 16 20 25 |
540- 560- 580- 600- 620- 640- |
24 22 16 2 6 1 |
13.4.2.1 数据准备
激活数据管理窗口,定义频数变量名为f,依次输入人数资料。
13.4.2.2 统计分析
激活Statistics菜单选Nonparametric Tests中的1-Sample K-S ...命令项,弹出One-Sample Kolmogorov-Smirnov Test 对话框(图13.6)。在对话框左侧的变量列表中选f,点击钮使之进入Test Variable List框,在Test Distribution框中选Normal项,表明与正态分布形式相比较,再点击OK钮即可。

图13.6 单样本Kolmogorov-Smirnov Z检验对话框
13.4.2.3 结果解释
在结果输出窗口中将看到如下统计数据:
K-S正态性检验的结果显示,Z值=0.7032,双侧P值=0.7060,可认为该地正常成年男子的红细胞计数符合正态分布。
|
F Test distribution - Normal Mean: 12.0000 Standard Deviation: 9.3808 Cases: 12 Most extreme differences Absolute Positive Negative K-S Z 2-Tailed P .20298本文系梅斯医学(MedSci)原创编译整理,转载需授权!-->
任何事物的存在都不是孤立的,而是相互联系、相互制约的。在医学领域中,身高与体重、体温与脉搏、年龄与血压等都存在一定的联系。说明客观事物相互间关系的密切程度并用适当的统计指标表示出来,这个过程就是相关分析。
值得注意,事物之间有相关,不一定是因果关系,也可能仅是伴随关系。但如果事物之间有因果关系,则两者必然相关。
SPS 回归分析是处理两个及两个以上变量间线性依存关系的统计方法。在医学领域中,此类问题很普遍,如人头发中某种金属元素的含量与血液中该元素的含量有关系,人的体表面积与身高、体重有关系;等等。回归分析就是用于说明这种依存变化的数学关系。
第一节 Linear过程
8.1.1 主要功能
调用此过程可完成二元或多元的线性回归分析 2.1 主要功能
在精神卫生与社会医学研究中,经常需要借助量表来了解对象的某一特性。如常用的症状自评量表(SCL-90)即用于评定对象精神病症状的表现形式与强度;又如生活事件量表(LES)即用于对精神刺激进行定性和定量分析。在完成一份量表的编制工作后,或在准备将一份已有的量表作实际应用前,需要对量表的信度进行考核。
& 对数线性模型是用于离散型数据或整理成列联表格式的计数资料的统计分析工具。在对数线性模型中,所有用作的分类的因素均为独立变量,列联表各单元中的例数为应变量。对于列联表资料,通常作χ2 检验,但χ2 检验无法系统地评价变量间的联系,也无法估计变量间相互作用的大小,而对数线性模型是处理这些问题的最佳方法。
第一节 General过程
9.1.1 主要功能
人们认识事物时往往先把被认识的对象进行分类,以便寻找其中同与不同的特征,因而分类学是人们认识世界的基础科学。在医学实践中也经常需要做分类的工作,如根据病人的一系列症状、体征和生化检查的结果,判断病人所患疾病的类型;或对一系列检查方法及其结果,将之划分成某几种方法适合用于甲类病的检查,另几种方法适合用于乙类病的检查;等等。统计学中常用的分类统计方法主要是聚类分析与判别分析。
&nbs 1 主要功能
多元分析处理的是多指标的问题。由于指标太多,使得分析的复杂性增加。观察指标的增加本来是为了使研究过程趋于完整,但反过来说,为使研究结果清晰明了而一味增加观察指标又让人陷入混乱不清。由于在实际工作中,指标间经常具备一定的相关性,故人们希望用较少的指标代替原来较多的指标,但依然能反映原有的全部信息,于是就产生了主成分分析、对应分析、典
|









#非参数检验#
44
#非参数#
31