
论文速读 | 大模型与医学人工智能
2023-12-10 美年健康研究院 美年健康研究院 发表于上海

本期内容涵盖医学领域多智能体协作的研究,中文医学大模型ChiMed-GPT和中医大模型HuatuoGPT-II,以及一个用于评估LLMs在较长医学文本上能力的医学数据集LongBoX。
颠覆性技术如大模型和人工智能正以迅猛的速度改变医疗健康领域。《论文速读》栏目旨在跟踪这些领域的最新进展,整理全球学术期刊中的前沿论文,帮助读者洞悉热门领域的最新趋势和突破。本期内容涵盖医学领域多智能体协作的研究,中文医学大模型ChiMed-GPT和中医大模型HuatuoGPT-II,以及一个用于评估LLMs在较长医学文本上能力的医学数据集LongBoX。期待与您共同探索大模型和医学人工智能领域的前沿科研成果。
01 Are we going MAD? Benchmarking Multi-Agent Debate between Language Models for Medical Q&A
◎ 摘要:近期大型语言模型(LLMs)的进展凸显了它们在回答医疗问题方面的潜力。然而,确保生成型智能体提供准确可靠的答案仍然是一个持续的挑战。在这种情况下,多智能体辩论(MAD)已成为提升LLMs真实性的一种重要策略。在这项工作中,我们提供了一个针对医疗问答的MAD策略综合基准,同时提供了开源实现。这探索了各种策略的有效利用,包括成本、时间和准确性之间的权衡。我们基于这些见解构建了一种基于智能体一致性的新型辩论提示策略,在医疗问答任务上优于先前发布的策略。
◎ 作者:Andries Smit, Paul Duckworth 等.
◎ 发表日期:2023-11-29
◎ 发表期刊:arXiv preprint
◎ 原文链接:https://arxiv.org/abs/2311.17371
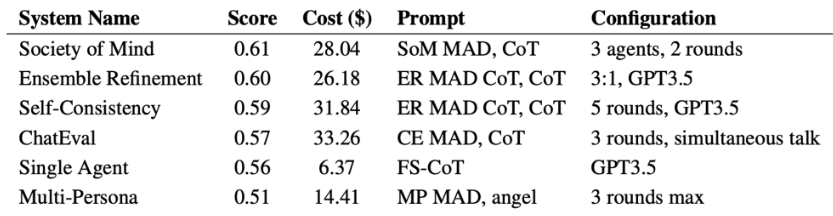
Table: Highest performing configuration for each QA system on MedQA dataset
02 ChiMed-GPT: A Chinese Medical Large Language Model with Full Training Regime and Better Alignment to Human Preferences
◎ 摘要:对优质医疗服务的需求不断增加,凸显了医疗基础设施的差异。随着大数据,特别是文本,成为医疗服务的基础,迫切需要针对医疗领域量身定制的有效自然语言处理(NLP)解决方案。传统方法利用预训练模型在这一领域呈现出有希望的结果,而当前的大型语言模型(LLMs)为医学文本处理提供了先进的基础。然而,大多数医学LLMs仅通过监督微调(SFT)进行训练,虽然它有效地赋予LLMs理解和响应医学指令的能力,但在学习领域知识和与人类偏好相一致方面效果不佳。另一个工程障碍是当前医学LLM限制了上下文长度(例如2,048个标记),使得LLMs难以处理在医学领域经常需要的长上下文。在这项工作中,我们提出了ChiMed-GPT,一个专门针对中国医学领域设计的新的基准LLM,上下文长度扩大到4,096个标记,并经过了包括预训练、SFT和RLHF在内的全面训练。对包括信息提取、问答和对话生成在内的真实世界任务的评估表明,ChiMed-GPT在通用领域LLMs上表现出卓越的性能。此外,我们通过要求ChiMed-GPT执行关于对患者歧视的态度量表,分析可能的偏见,以促进医学领域LLMs的负责任发展。
◎ 作者:Yuanhe Tian, Ruyi Gan 等.
◎ 发表日期:2023-11-23
◎ 发表期刊:arXiv preprint
◎ 原文链接:https://arxiv.org/abs/2311.06025
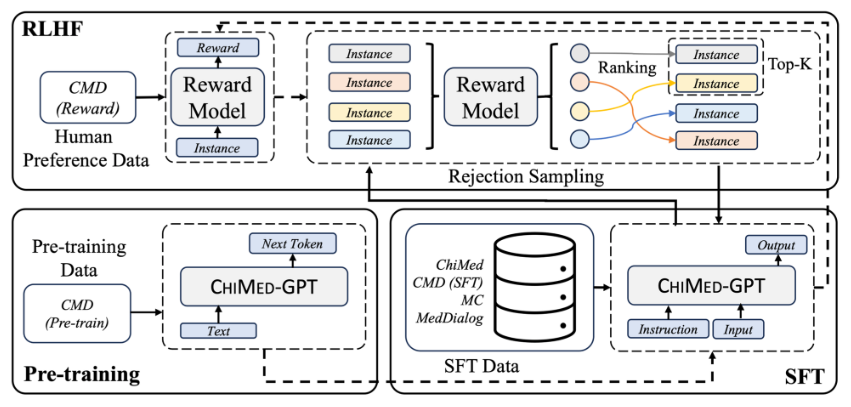
Fig.: An illustration of the overall training process of the CHIMED-GPT, which consists of three stages including pre-training, supervised fine-tuning, and reinforcement learning from human feedback (RLHF).
03 PEFT-MedAware: Large Language Model for Medical Awareness
◎ 摘要:聊天模型能够回答各种问题,但是它们的回答准确性很不确定。在这项研究中,我们提出了一种专门的PEFT-MedAware模型,其中我们利用参数高效微调(PEFT)来增强Falcon-1b大型语言模型在专门的MedQuAD数据上的性能,该数据包含16,407个医学问答对,仅利用其可训练参数的0.44%以提高计算效率。本文采用数据预处理和PEFT来优化模型性能,并通过BitsAndBytesConfig进行高效的Transformer训练。结果表明,该模型能够在特定领域的医学问答任务中胜过其他语言模型,利用有限的计算资源提高准确性,适用于资源受限环境中的部署。我们提出通过扩展数据集、使用更大的模型和反馈机制来进一步改进,以保持医学相关性。我们的工作突显了PEFT在医疗人工智能中的高效性和专业能力,无需过多的资源需求即可超越标准模型的精确性。所提出的模型和数据仅供研究目的发布。
◎ 作者:Keivalya Pandya
◎ 发表日期:2023-11-17
◎ 发表期刊:arXiv preprint
◎ 原文链接:https://arxiv.org/abs/2311.10697
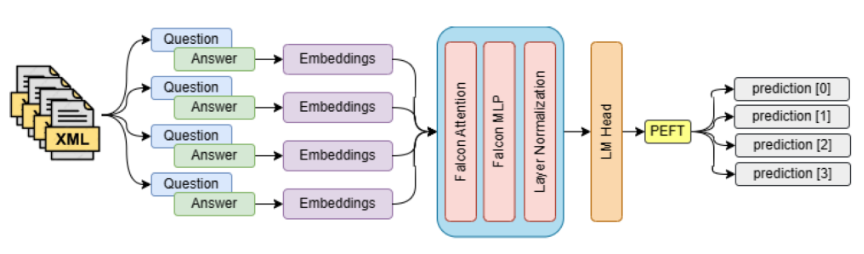
Fig.: peft-MedAware Pipeline
04 MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning
◎ 摘要:大型语言模型(LLM)在各个通用领域取得了显著的进展,但在医学和医疗领域仍面临重大障碍。这个领域面临着特殊挑战,如领域专用术语和对专业知识的推理。为了解决这些难题,我们提出了一种新颖的多学科协作(MC)框架,用于医学领域,利用基于LLM的角色扮演代理人参与协作多轮讨论,从而增强LLM的熟练程度和推理能力。这种无需训练且可解释的框架包括五个关键步骤:收集领域专家、提出个体分析、将这些分析总结成报告、在讨论中进行迭代直到达成共识,最终做出决策。我们的工作特别关注零-shot情景,我们在九个数据集(MedQA、MedMCQA、PubMedQA和来自MMLU的六个子任务)上的结果表明,我们提出的MC框架在挖掘和利用LLM中的医学专业知识以及扩展其推理能力方面表现出色。基于这些结果,我们进一步进行人工评估,以确定和分类我们方法中的常见错误,以及针对各种因素对整体性能的影响进行消融研究。
◎ 作者:Xiangru Tang, Anni Zou 等.
◎ 发表日期:2023-11-16
◎ 发表期刊:arXiv preprint
◎ 原文链接:https://arxiv.org/abs/2311.10537
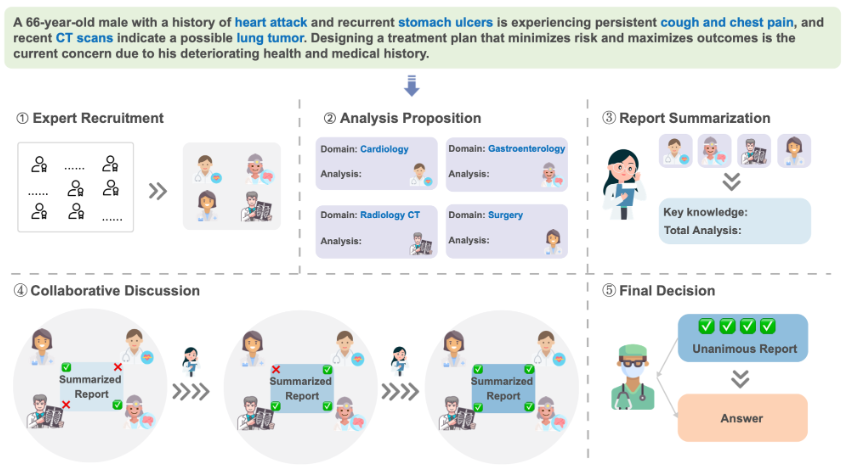
Fig. : A Diagram of our proposed multi-disciplinary collaboration framework. Given a medical question as input, the framework performs reasoning in five stages: (i) expert gathering: distinct domain experts are assembled based on the nature of the clinical question; (ii) analysis proposition: each expert, using their specific disciplinary knowledge, puts forward an analysis; (iii) report summarization: a consolidated report is generated incorporating all experts’ analyses; (iv) collaborative discussion: the experts review, discuss, and refine the report iteratively until a consensus is reached; (v) decision making: a final decision, reflecting unanimous agreement among all experts, is derived from the report.
05 LongBoX: Evaluating Transformers on Long-Sequence Clinical Tasks
◎ 摘要:许多大型医学语言模型(LLMs)主要在短文本上进行评估,它们处理完整的电子健康记录(EHR)等较长序列的能力尚未进行系统研究。在长序列上评估这些模型是至关重要的,因为先前在通用领域的工作已经证明了LLMs在较长文本上的性能下降。受此启发,我们引入了LongBoX,这是一个以文本到文本格式设计的七个医学数据集,旨在研究模型在长序列上的性能。初步实验显示,无论是医学LLMs(例如BioGPT)还是强大的通用领域LLMs(例如FLAN-T5),在这个基准上都表现困难。我们进一步评估了两种用于处理长序列的技术:(i)局部-全局注意力和(ii)解码器中的融合(FiD)。我们的结果显示长序列处理的效果参差不齐 - 虽然某些数据集上的分数有所提高,但还有很大的改进空间。我们希望LongBoX促进了更有效的医学领域长序列技术的发展。
◎ 作者:Mihir Parmar, Aakanksha Naik 等.
◎ 发表日期:2023-11-16
◎ 发表期刊:arXiv preprint
◎ 原文链接:https://arxiv.org/abs/2311.09564

Table: Performance of long document techniques, LongT5 and FiD, on LONGBOX. All results are presented in %. Green indicates improvement and red indicates degradation in performance compared to the best performing Enc. + Dec. model.
06 HuatuoGPT-II, One-stage Training for Medical Adaption of LLMs
◎ 摘要:将语言模型适应到特定领域,即“领域自适应”,是一种常见的做法,当专业知识(例如医学)没有包含在像Llama2这样的通用语言模型中时。挑战在于两个训练阶段之间数据的异质性,因为它在语言、体裁或格式上有所不同。为了解决这个问题并简化学习协议,我们提出将来自预训练和监督阶段的异构数据转化为统一的简单输入-输出对格式。我们在ChatGPT等专有LLM在传统中医等领域表现相对较差的领域中验证了新协议。开发的模型HuatuoGPT-II在中医领域的许多基准测试中展现了最先进的性能,例如医疗执业考试。在某些方面,它甚至超过了ChatGPT和GPT-4等专有模型,特别是在传统中医领域。专家的手动评估进一步验证了HuatuoGPT-II相对于现有LLM的优势。值得注意的是,HuatuoGPT-II在中国国家医疗执业考试中进行了基准测试,并取得了最佳表现,展示了它的有效性和泛化能力。
◎ 作者:Junying Chen, Xidong Wang 等.
◎ 发表日期:2023-11-16
◎ 发表期刊:arvXiv preprint
◎ 原文链接:https://arxiv.org/abs/2311.09774
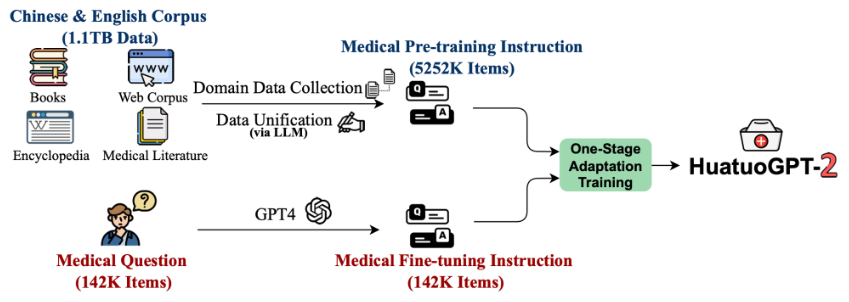
Figure: Schematic of HuatuoGPT-II.
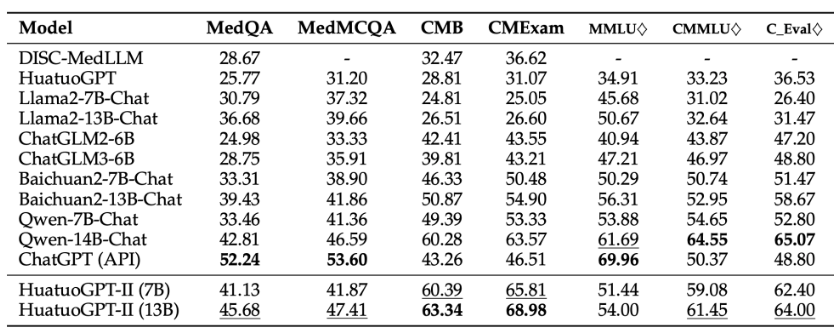
Table: Medical benchmark results. Evaluation was done using validation data for MedQA, MedMCQA, and CMB. ♢ signifies extraction of only medical-related questions. ’-’ indicate that the model cannot follow question and make a choice.
07 Do Physicians Know How to Prompt? The Need for Automatic Prompt Optimization Help in Clinical Note Generation
◎ 摘要:本研究旨在探讨提示工程对大型语言模型(LLMs)在临床笔记生成中的性能影响。我们引入了自动提示优化(APO)框架来优化初始提示,并比较了医学专家、非医学专家和APO增强的GPT3.5和GPT4的输出结果。结果表明,GPT4 APO在标准化临床笔记各个部分的提示质量方面表现出优越性能。人机协同方法显示,专家在APO后保持内容质量,并偏好自己的修改,这表明专家定制化的价值。我们建议采用两阶段优化过程,利用APO-GPT4实现一致性,专家参与进行个性化定制。
◎ 作者:Zonghai Yao, Ahmed Jaafar 等.
◎ 发表日期:2023-11-16
◎ 发表期刊:arXiv preprint
◎ 原文链接:https://arxiv.org/abs/2311.09684
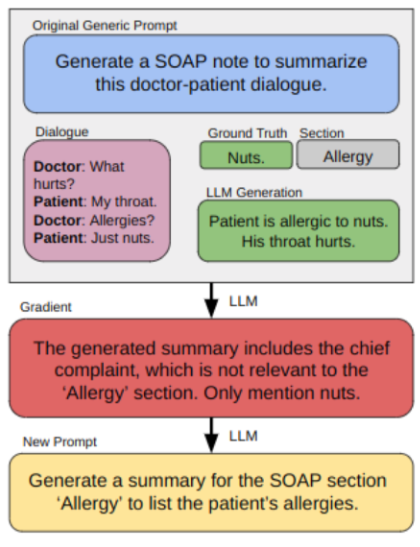
Figure: Overview of APO on clinical note generation.
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言







#模型# #人工智能#
37