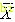
SPSS教程2:利用SPSS进行统计描述
2012-04-12 生物谷 生物谷

一、统计描述方法 在教育技术研究过程中收集到大量的资料数据,但从这些杂乱无章的资料中,很难对其总体水平与分布状况做出评价判断。因此,必须采用一些适当的方法对这些资料进行处理,使之简约化、分类化、系统化,从中发现它们的分布规律,掌握总体的特征,以便对其水平做出客观的评价。 统计描述方法,是研究简缩数据并描述这些数据的统计方法。将搜集来的大量数据资料,加以整理、归纳和分组,简缩成易于处理和
一、统计描述方法
在教育技术研究过程中收集到大量的资料数据,但从这些杂乱无章的资料中,很难对其总体水平与分布状况做出评价判断。因此,必须采用一些适当的方法对这些资料进行处理,使之简约化、分类化、系统化,从中发现它们的分布规律,掌握总体的特征,以便对其水平做出客观的评价。
统计描述方法,是研究简缩数据并描述这些数据的统计方法。将搜集来的大量数据资料,加以整理、归纳和分组,简缩成易于处理和便于理解的形式,并计算所得数据的各种统计量,如平均数、标准差、以及描述有关事物或现象的分布情况、波动范围和相关程度等,以揭示其特点和规律。
(一)数据资料的整理和表示
在教育技术研究中,我们用各种方法搜集来的资料,一般是零散的,它只反映个别现象的个别特征,必须经过整理加工,使之系统化,才能计算统计指标,进行统计分析,为进一步研究提供有用的信息,首先要进行的是统计整理,它包含以下几部分内容:
1.数据检查
主要检查数据的完整性与正确性。统计资料完整性的检查,就是要根据调查项目检查是否填写齐全,避免遗漏,删去重复。正确性检查,就是检查搜集的资料是否真实可靠。特别是统计数字的真实性是统计工作的生命,统计资料的检查整理必须抓紧这一环。
数据检查可分为逻辑检查和计算检查两种方法。逻辑检查,是从理论和一般常识上来检查资料内容是否合理,指标之间是否矛盾。计算检查是检查统计数字在计算方法和计算结果上有否错误。
2.数据分类
数据分类就是把搜集来的数据进行分组归类。数据分类要做到既不重复、不遗漏,又不混淆,一般又可分为品质分类和数量分类。
品质分类:是按事物性质划分为不同的组别、种类。如以性别为标志可分为男与女;按“理解能力”、“学习态度”等为标志,又可分为好、较好、一般、差等几种水平,每种水平可看成类,每一类可给以相当的数量。可以通过各类所包含的数据再进行数量化的比较和分析。
数量分类:是按数量的属性分类。有顺序排列法、等级排列法和次数分布法等。
⒊ 数据的排序
数据排序:将各数据从大到小或从小到大进行排列。这样就可以看出最高分和最低分是多少,各分数出现的次数和位于中间的是什么数等。包括等级排列和次数排序。
等级排列:即根据顺序排列划分等级。但与顺序排列不同,它是按数值所含的意义确定的。若是学习成绩,应以数值大的排为第一等级;若是反映时间,则将最小的数值排为第一等级。
次数排序:即根据在指定的数值范围内,数据出现的频数大小排序。
⒋ 数据统计表
就是把所研究的教育技术现象和过程的数字资料,以简明的表格形式表现出来。它可以避免文字的冗长叙述,便于比较各项目之间的相互关系,便于总计、平均和其他统计值的计算,便于检查计算错误和项目遗漏。
⒌ 数据的图示法
数据的图示法是利用几何图形或其他图形等的描绘,把所研究对象的特征、内部结构、相互关系和对比情况等方面的数据资料,绘制成整齐简明的图形。它是用以说明研究对象和过程的量与量之间对比关系的一种方法。它能准确地表现统计资料,有助于对统计资料进行比较、对照、分析和研究。图示法,具有直观、形象,便于记忆和思考以及表达语言难以说清的内容之优点。
在教育技术研究中常用的有条形图、曲线图、直方图和圆形图等,其绘制方法是大家所熟知的,这里不作介绍。
(二)特征参数的计算
为了分析研究对象总体的特征,不必对总体中每一个单位都进行研究。而是通过抽样方法,按照随机性原则,从全部对象中,只抽取部分单位(样本组)加以研究,对于每组样本,首先应对其基本特征参数进行计算,以给出整体特征的统计描述。并根据统计数据,对总体对象作出具有一定可靠程度的估计和推测。常用的特征参数包括:
⒈ 集中量数
(1)算术平均数,用![]() 表示,设
表示,设![]() 为各次观察的结果,则有:
为各次观察的结果,则有:

上式中,![]() 表示平均分
表示平均分![]() 表示每个学生的得分,n表示学生人数。
表示每个学生的得分,n表示学生人数。
(2)中数,是指一组按大小顺序排列起来的量数中的中间点的数,又称中位数,用Mdn来表示。
(3)众数,是指一列数中出现次数最多的数值,常用M表示。
2.差异量数
|
- |
差异量数是表示量数之间的差异程度的一些统计量的总称,它是用以表示一群量数的离散情况或离中趋势。 |
集中量数在量尺上是一个点,表示各量数所在的位置。差异量数在量尺上是一段距离,表示一个量数与另一个量数或中心点之间的距离。只有知道了差异量数的大小,才能了解集中量数的代表性如何。差异量数愈大,集中量数的代表性愈小;差异量数愈小,则集中量数的代表性愈大。
在统计分析中经常应用的是标准差,它是与平均数的差数的平方和的平均数的算术平方根。
![]()
上式中,S为标准差
![]()
![]() ,为每个学生的得分与平均分的离差,上述公式计算步骤如下:
,为每个学生的得分与平均分的离差,上述公式计算步骤如下:
(1)先求出各数据与平均分的离差![]()
![]() ;
;
(2)求各个离差的平方和![]() ;
;
(3)将![]() 除以n再开方,即得标准差。
除以n再开方,即得标准差。
3.标准分数
|
- |
标准分数,又称Z分数。是以标准差为单位表示一个分数在团体分数中所处的位置。 |
标准分数的计算公式:

公式中x-原始分数, ![]() -平均分数,S-标准差。
-平均分数,S-标准差。
(三)次数分布
|
- |
次数分布又称次数分配。是指总体或样本按随机变量(数据)大小次序在出现频率上的排列。 |
一般采用次数分布表、次数分布直方图或次数分布曲线来表示。
【例6-1】 现有50名学生的成绩,原始数据如表6-1所示:(n=50)

1.次数分布表
为了显示该组样本在不同分数段中的次数分布情况,我们对该数组进行次数分布统计,编制出该数组的次数分布表。方法如下:
(1)求全距:最大数-最小数=98-51=47
(2)定组数,一般10-20组为宜。
(3)定组距,组距=(全距+1)/组数=(47+1)/10=4.7(取5)
(4)定组限,95-100,90-95,85-90……等
(5)求组中值:组中值=(上限+下限)/2,如95-100一组,
其组中值=(100+95)/2=97.5
(6)归类 把原始数据,分别归到相关组中,得出次数分布表如表6-2所示:
2.次数分布曲线
根据这个次数分布表,可绘出对应的次数分布直方图、次数分布曲线和积累次数曲线,分别如图6-8、图6-9和图6-10所示。为了分析次数分布曲线的特征,我们可以把它与正态分布曲线相比较来进行研究。



3. 正态分布曲线
正态分布是一种理论分布,在次数分布中,中间的次数多,由中间往两边的次数逐渐减少,且两边的次数多少是相等的。根据正态分布绘成的曲线称为正态分布曲线,正态分布曲线形状如钟形,它的特点是中间成一高峰,由高峰向两侧逐渐下降,先向内弯,后向外弯,降低的速度是先慢后快,以后又再次减慢,最后达到接近底线,但永远不与底线相接,形成一个单峰的对称的钟形形态,如图6-11所示。
正态分布曲线的形状和位置由平均分![]() 和标准差S所决定。平均分
和标准差S所决定。平均分![]() 对应于单峰位置,
对应于单峰位置,![]() 越大,曲线越往右移动。标准差S越大,曲线的单峰高度越低,宽度越大,显得越“胖”;S越小,曲线的高度越高,宽度越小,显得越“瘦”。如图6-5所示。
越大,曲线越往右移动。标准差S越大,曲线的单峰高度越低,宽度越大,显得越“胖”;S越小,曲线的高度越高,宽度越小,显得越“瘦”。如图6-5所示。

在正态分布曲线图上,正态曲线以下,以S为距离单位所包括的面积是按一定比例分配的,若将正态曲线底边从-3S到3S分成四等分,每等分距离为1.5S,则每距离间隔之间所包括的面积比例如表6-3和图6-12所示。

利用正态分布曲线这些性质,我们可以得到划分不同学习水平等级的界限和学生人数比例的理论数值。例如对于常态![]() =75,S=10的情况,其优、良、中、差各等级的分数范围和人数比例应如表6-4所示(N=30)。
=75,S=10的情况,其优、良、中、差各等级的分数范围和人数比例应如表6-4所示(N=30)。
按照上述方法,对于一个给定的样本组N=3 0,得知其平均分
0,得知其平均分![]() =83,标准差S=7.78,我们便可以得到学习水平等级的划分界线,并将人数比例的理论数和实际数相比较,如表6-5所示。
=83,标准差S=7.78,我们便可以得到学习水平等级的划分界线,并将人数比例的理论数和实际数相比较,如表6-5所示。

根据图6-12和表6-4,我们便可以得到如下结论:
(1)样本组的峰值位置位于![]() 的右侧,属于正偏态的情况。
的右侧,属于正偏态的情况。
(2)样本组的水平等级标准较高,分数要在94.7以上才能达到优等,而在71.3以下便认为是差等。
(3)样本组中优、良等级的实际人数(1+17)要比理论数(15人)所占的比例为多。
因此可以认为该总体属于平均水平较高的整体。
[1] [2] [3] 下一页
二、![]() -S平面特征数据分析模型
-S平面特征数据分析模型
为了综合地、直观地考察样本组的整体统计特征,我们给出一个![]() -S平面分析模型,如图6-13。模型中的横坐标表示平均分的大小(
-S平面分析模型,如图6-13。模型中的横坐标表示平均分的大小(![]() ),而纵坐标则表示标准差(S)的大小,坐标原点以常态作参考标准(
),而纵坐标则表示标准差(S)的大小,坐标原点以常态作参考标准(![]() =75,S=10)。用
=75,S=10)。用![]() 、S两个参数,可以确定样本组落在平面的某一个象限,而不同的象限,将代表样本组具有不同的统计特征。为了说明各象限所代表的意义,表6-6给出了四组不同特征的数组,它们将分别位于不同的象限,具有不同的特点。利用平均分
、S两个参数,可以确定样本组落在平面的某一个象限,而不同的象限,将代表样本组具有不同的统计特征。为了说明各象限所代表的意义,表6-6给出了四组不同特征的数组,它们将分别位于不同的象限,具有不同的特点。利用平均分![]() 和标准差S所在的位置,我们可以直观地看到样本组成绩的统计特征。
和标准差S所在的位置,我们可以直观地看到样本组成绩的统计特征。


【例6-2】 某班语文平均考试成绩为74分,标准差8分。甲学生得90分,乙学生为72分。通过标准分数的计算可以得知他们在全体同学中所出的位置。
![]()
![]()
(1)平均分
![]()
(2)标准差
按照求S步骤进行计算,可得到![]() =1819,代入公式(10-2)便可得到标准差S
=1819,代入公式(10-2)便可得到标准差S
![]()
对于这一组数据,由于![]() =83>75,S=7.78<10,它处于第四象限,属于平均水平较高,且相对集中的水平。
=83>75,S=7.78<10,它处于第四象限,属于平均水平较高,且相对集中的水平。
三、利用SPSS进行统计特征分析
【例6-3】 现有学生24人,分成两小组,在某一次期中测验中,某学科测验成绩如表6-7所示。试利用SPSS对该班学生成绩进行等级排序,并计算总平均分、总标准差,再分别计算两组学生的平均分和标准差。根据处理结果,分析两组学生成绩的统计特征。

操作步骤:
⒈ 录入数据
录入数据的过程分为两个步骤,一是定义变量,二是录入变量值。
(1)定义变量:“学号”、“组别”与“成绩”。
(2)录入变量值:在数据编辑窗口中,按照表1的内容,将各变量值一一录入。录入后的部分界面如图6-14所示。
⒉ 数据的等级排序
(1)选择“Data→Sort Cases”命令,弹出“Sort Cases”对话框,把“成绩”变量选入“Sort by”中,并在Sort Order中选择“Descending(降序)”选项,将学生成绩按降序排列,如图6-15所示,单击“OK”按钮。

(2)排序结果
排序结果在数据编辑窗口可以即时浏览,如图6-16所示,并可以通过选择“File→Print…”命令,将结果打印输出。

⒊ 平均分与标准差的计算
(1)计算总平均分与标准差
① 选择“Analyze→Descripitive Statistic→Descripitives…”命令,弹出“Descripitive”对话框,从左侧将“成绩”变量选入“Variables”栏中,如图6-17所示。

② 单击“OK”按钮,提交运行,输出结果如表6-8所示。

(2)分别计算两组学生的平均分和标准差
由于录入数据时两组数据是混合一列,所以在统计之前要将两组学生的数据拆分,在进行统计处理。
① 数据拆分
选择“Data→Split File…”命令,弹出“Split File”对话框,激活“Organize by group”选项,从左侧选择“性别”变量进入“Groups Based on”栏目,最后激活“Sort the file by grouping variables”选项,如图6-18所示。单击“OK”按钮。

② 与计算总平均分与标准差相同,选择“Analyze→Descripitive Statistic→Descripitives…”命令,弹出“Descripitive”对话框,从左侧将“成绩”变量选入“Variables”栏中。如图6-17所示。
③ 单击“OK”按钮,提交运行,输出结果如表6-9所示。

⒋ 统计特征分析
根据SPSS的统计处理所得结果如表6-10所示。

上一页 [1] [2] [3] 下一页
四、次数分布表的形成
【例6-4】 根据表6-1中给出的50名学生的学习成绩,计算60分以下,60-70,70-80,80-90,90分以上的次数分布表。
操作步骤:
1.录入数据
定义变量“学号”和“成绩”,并按表3内容输入数据
2.转换数据,生成新变量
(1)选择“Transform→Recode→Into Different Varibles…”命令,弹出“Recode into Different Variables”对话框,将“成绩”选入“Numeric Variable”框中,并在“Output Variable”中输入新变量的名字“分组”,单击框后的“Change”按钮,如图6-19所示。

(2)单击“Old and New Values…”按钮,弹出“Recode into Different Variables:Old and New Values”对话框。
在对话框中左侧第二个“Range”框中输入60,然后在“New Value”框中的“Value”后输入1,单击“Add”按钮,右侧的文本框中显示“Lowest thru 60→1”,表示用1代表60以下的分数。
在第一个“Range”框中输入“60”though“70”,然后在“Value”后输入2,单击“Add”按钮加入,即用2代表60到70之间的分数。同样,用3代表70到80之间的分数,用4代表80到90之间的分数。
在第三个“Range”框中输入“90”,然后在“New Value”框中的“Value”后输入5,单击“Add”按钮加入,即用5代表90以上的分数。
设置完成后如图6-20所示。

(3)单击“Continue”按钮,回到图11的对话框中,单击“OK”按钮,生成新的变量“分组”,界面如图6-21所示。

3.统计分析
(1)选择“Analyze→Descriptive Statistic→Frequencies”命令,弹出“Frequencies”对话框,从左侧选择“分组”,使其进入“Variable(s)”框中,如图6-22所示。

(2)选中“Display frequency tables”复选框,表示显示次数分布表。
(3)单击“Statistics”按钮,弹出“Frenquency:Statistics”对话框,视需要进行选择,如图6-23所示。本例中采用默认值,设置完成后单击“Continue”按钮。
(4)在图6-22所示的对话框中,单击“Charts”按钮,弹出“Frenquencies:Charts”对话框,如图6-24所示。本例中选择“Histograms”(直方图)和“With normal curve”(带有正态曲线)两项,单击“Continue”按钮。

(5)在图6-22所示的对话框中,单击“Format”按钮,弹出“Frenquencies:Format”对话框,如图6-25所示。本例中取默认值,设置完成后单击“Continue”按钮。

(6)在图6-22所示的对话框中,单击“OK”按钮,提交运行,输出结果如表6-11所示。


4.结果分析
根据表6-11的输出结果可知,在60分以下的有8人,60-70分之间的有6人,70-80分之间的有12人,80-90之间的有18人,90分以上的有6人。
上一页 [1] [2] [3]
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言






详尽啊,要都消化了得多牛!~
132