
小知识:标准差与标准误的联系与区别
2014-05-09 MedSci MedSci原创

标准差表示数据的离散程度,或者说数据的波动大小。标准误表示抽样误差的大小。统计教材上一般都写标准误表示均数的抽样误差,这对于初学者很难理解。这里通过举例来说明含义。比 如,有一个学校,学校中共有1000名学生,则这1000名学生可以作为这个学校学生的总体。如果我想了解所有学生的身高,采用随机抽样,抽取了50人。 这50人就是一个样本。这里需要注意:一个样本并不是指一个人,而是指一次抽样。一个样
标准差表示数据的离散程度,或者说数据的波动大小。标准误表示抽样误差的大小。
统计教材上一般都写标准误表示均数的抽样误差,这对于初学者很难理解。这里通过举例来说明含义。
比如,有一个学校,学校中共有1000名学生,则这1000名学生可以作为这个学校学生的总体。如果我想了解所有学生的身高,采用随机抽样,抽取了50人。
这50人就是一个样本。这里需要注意:一个样本并不是指一个人,而是指一次抽样。一个样本可以是1个人,也可以是100人,这里的1和100就是样本大小。
从理论上讲,抽样误差表示这样的意思:即如果不止抽样一次,而是抽样10次,每次都50人,那么我就有10个均数和标准差。例如下图,大圈代表总体1000人,一个小圈代表一个样本,即50人。每个样本都能计算计算一个均数和标准差。
以这10个均数作为原始数据,仍然能计算出一个均数和标准差,以这10个均数计算出的标准差就称之为标准误。这是理论上的含义,实际的含义就代表抽样误差的大小,即抽取的样本代表性好不好,抽样误差越小,代表性越好,反之,代表性越差。
如果我对学校中的1000人都测量了身高,那理论上就没有标准误,也就是没有抽样误差了,因为我测量了总体,这时就不存在标准误了。但是标准差是存在的,因为这1000人的身高肯定不同,肯定会有波动。这里就充分表明了标准差和标准误的区别了。
标准差与标准误的意义、作用和使用范围均不同。标准差(亦称单数标准差)一般用s 表示,是表示个体间变异大小的指标,反映了整个样本对样本平均数的离散程度,是数据精密度的衡量指标;而标准误一般用Sx 表示,反映样本平均数对总体平均数的变异程度,从而反映抽样误差的大小,是量度结果精密度的指标。

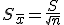
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言




#小知识#
26
需要明确的概念
156