关于样本量的几个小问题
2020-02-05 王晓晓,赵一鸣 临床流行病学和循证医学

首先,大家看一个样本量估算的结果(基于PASS软件),N1=N2=37,每组需要37人。哇,好开心,每组入组37人就行了。1、好像不是这样,因为根据公式或软件估算的样本量是在给定条件下满足研究所需的最小样本量。也就是说,最终纳入统计分析时,每组至少需要37人。临床研究中,常会因为各种原因导致研究对象的脱落和失访,因此,我们要提前考虑到失访的情况,一般在此基础上增加5%~20%。2、考虑失访,大家一

首先,大家看一个样本量估算的结果(基于PASS软件),N1=N2=37,每组需要37人。哇,好开心,每组入组37人就行了。
1、好像不是这样,因为根据公式或软件估算的样本量是在给定条件下满足研究所需的最小样本量。也就是说,最终纳入统计分析时,每组至少需要37人。临床研究中,常会因为各种原因导致研究对象的脱落和失访,因此,我们要提前考虑到失访的情况,一般在此基础上增加5%~20%。
2、考虑失访,大家一般都不会忽略。比如估算样本量每组37人,考虑20%的失访,每组计划纳入45人。最后每组各40人数据完整可以纳入分析,那么问题来了,我们是不是必须保证分析时每组只有37人呢?
只要我们还记得每组37人是满足研究所需的最小样本量,也就是说每组大于等于37人。那我们就不会有这种疑惑了,直接对每组40人的数据进行分析即可。
3、有人说,样本量多了研究结果可信度高,那我就尽可能纳入多一些。估算样本量每组37人,计划每组纳入56人(增加了50%),这样可以吗?
3.1、好像没问题,适当增加样本量可提高研究结果的可信度。毕竟,样本量估算的效应量和实际研究的效应量也还是有差距的。但是,大家需要注意一点,那就是考虑到对患者利益的保护。
3.2、对于观察性研究,比如横断面、病例-对照研究、队列研究,研究本身对患者无额外风险,在这种情况下,适当增加样本量是可以接受的。
3.3、但是,如果是干预性研究,当我们已经收集到研究所需的样本量时,而再去额外的多纳入研究对象,这时候就对于接受疗效较差药物或方案的研究对象就存在伦理问题了。因此,干预性研究,建议在软件或公式估算样本量的基础上,适当增加5%~20%。
4、例子中,每组比例为1:1,好像也听到说1:1时统计效能最大,是不是每组样本量必须一样呢?
4.1、我们说组间比例1:1时,统计效能最大,是指当总的样本量一定时,组间比例1:1,统计效能最大。比如,100:100的统计效能大于150:50、120:80等等。
4.2、那我们估算样本量时,应该怎么设置组间比例呢?要考虑到可行性问题,比如罕见病的病例-对照研究,有可能要考虑对照多病例少的组合。而对于干预性研究,应尽可能减少安慰剂或阴性对照的比例。
4.3、一般我们建议组间比例在1:1~1:4之间。这是因为,当样本量估算的其他参数不变时,随着组间比例的增加,统计效能逐渐增大。但是当组间比例为1:4,此后增加组间比例,对统计效能的贡献较小,但组间比例的增加,也会引发因样本量增加导致的其他问题,综合考量,建议组间比例为1:1~1:4之间。
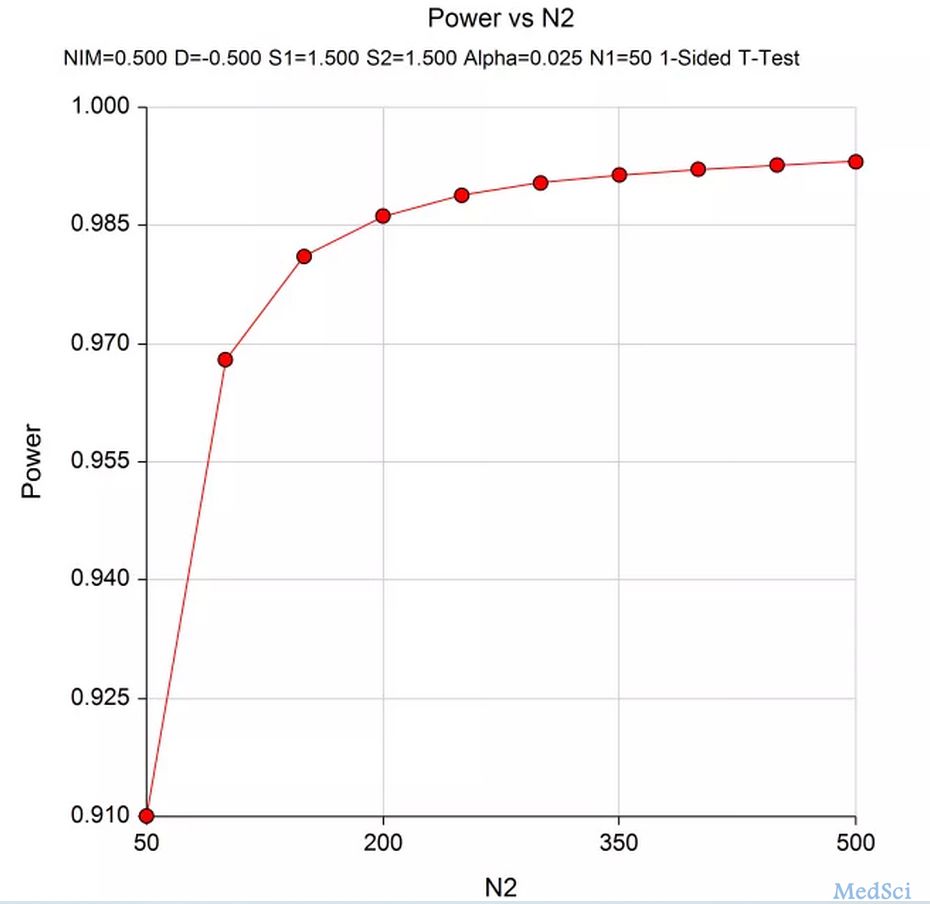
N1=50,N2在50-500之间,即组间比例为1:1-1:10时的统计效能。
小提示:本篇资讯需要登录阅读,点击跳转登录
版权声明:
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言






很棒,解释详细明了
71
#样本#
24
#样本量#
42