
Heckman两阶段模型:选择偏倚强大校正工具,原理及实现方法
2022-08-23 MedSci原创 MedSci原创

Heckman两阶段模型适用于解决由样本选择偏差(sample selection bias)造成的内生性问题。在经济学领域,样本选择偏差的典型例子是研究女性的受教育情况对女性工资的影响。按照这个思路
Heckman两阶段模型适用于解决由样本选择偏差(sample selection bias)造成的内生性问题。在经济学领域,样本选择偏差的典型例子是研究女性的受教育情况对女性工资的影响。按照这个思路,一般会去问卷收集或在哪个网站下载部分女性的受教育情况,工资,及其他特征数据,例如年龄,毕业院校等级等个人特征,然后做回归。不过这样做有一个问题,就是登记的女性,都是在工作的,但是许多受教育程度较高的女性不工作,选择做家庭主妇,这部分样本就没有算在内,样本失去随机性。这就导致模型只是用到了在工作的女性,这样得出的结论是有偏差的。在管理学领域,一个典型的问题是企业的某个特征,或者董事/CEO的某个特征,对企业R&D投入的影响。也是同样的问题,企业的R&D投入是企业自愿披露的内容,有的企业不披露,这时你做回归时就不能包括这部分样本,也会造成样本选择偏差,结果有偏。 对于这种情况,Heckman提出了一个方法,赫克曼矫正法(Heckman Correction,又称两阶段方法)。赫克曼矫正法分两个步骤进行: 第一步骤,研究者根据管理学理论设计出一个计算企业披露R&D投入概率的模型,而该模型的统计估计结果可以用来预测每个个体的概率; 第二步骤,研究者将这些被预测个体概率合并为一个额外的解释变量,与其他控制变量等变量一起来矫正自选择问题。这个比率叫逆米尔斯比率,inverse Mills ration, imr,也就是说,在第一步计算出imr,在第二步把imr当作一个控制变量。 以企业R&D投入问题为例,假设全样本是1000家公司,其中800家公司披露了其R&D投入。 第一阶段的模型,是一个包括全样本(1000家)的Probit模型,用来估计一家公司是否会披露其R&D投入的概率。这里的因变量是二元的,表示是否披露R&D投入;自变量是一些会影响是否披露R&D的外生变量,比如其他收入营业收入,杠杆率,公司规模,所属行业等等。然后根据这个Probit模型,为每一个样本计算出imr,imr作用是为每一个样本计算出一个用于修正样本选择偏差的值。 第二阶段,在原来的回归方程,也就是原来只有800家公司的样本的方程假如imr作为控制变量,其他都不变,然后估计出回归参数。这时不管imr需要显著,imr显著性和系数表明了样本选择偏差是否存在以及方向,说明样本选择偏差的确影响了你最初模型的估计,这正表明了使用Heckman两步法纠正样本选择偏差的必要性。imr不显著说明原模型不存在严重的样本选择偏差,这时Heckman第二步得到的结果应该与原模型得到的结果差不多(需要比对一下)。第二步关注的对象是核心解释变量是否显著。只要核心解释变量显著,就说明结果稳健。 小编此次搜集到了heckman两阶段模型的stata do代码以及计算数据案例,有需要的朋友千万不要错过! 首先,计算全部样本的IMR;随后,将遗漏变量IMR代入原回归方程中,具体来说: 第一步 : 用probit方法估计选择方程,其中原回归方程的被解释变量y是否被观测到或是否取值的虚拟变量y_dummy作为probit的被解释变量,解释变量包括原回归方程所有解释变量和至少一个外生变量,该外生变量只影响y是否取值,而不影响y的大小,即满足相关性和外生性的要求(但不是工具变量)。估计出所有变量的系数后,将样本数据代入至probit模型中,计算出拟合值 y_hat,再将y_hat代入风险函数中计算出IMR。 有四点需要注意: (2)选择方程的被解释变量只能是原回归方程中被解释变量y是否被观测到或是否取值的虚拟变量,而不能是其他变量,更不能是解释变量是否取值的虚拟变量。如果第一步回归的被解释变量是原回归中解释变量是否取值的虚拟变量,那么该模型就不再是样本选择模型了,关于这一点,实际应用中经常被搞混。 (3)第一步选择方程的解释变量必须要包括原回归中所有解释变量和至少一个外生变量,也就是说,原回归的解释变量是选择方程解释变量的真子集。如果只使用原回归中一部分的解释变量或不引入外生变量,那么就不能确保IMR与原回归的随机干扰项不相关,从而造成估计系数依然存在偏误。实际应用中,多数文献并未引入外生变量,部分文献甚至没有汇报第一步选择方程中的解释变量,这样的做法十分不推荐。此外,论文中如果引入了外生变量,就需要对相关性与外生性进行具体说明,其中相关性不能只从外生变量的回归系数显著这一个方面进行说明,还要从其他文献和从理论上进行分析;外生性的说明与之类似。 (4)第一步选择方程只能使用probit模型进行回归,不能使用logit模型。在选择方程中,假设扰动项服从正态分布,从而可以推导出将IMR代入原回归方程可以缓解样本选择偏差问题,因此对于被解释变量为0-1型的虚拟变量,只能使用probit模型而不能使用logit模型,因为logit模型不具有扰动项服从正态分布的假设。但问题是,probit假设时间效应和个体效应与扰动项不相关,即第一步选择方程中只能使用随机效应模型,不能使用更一般化的固定效应模型。实际应用中,多数文献在汇报第一阶段回归结果时,在末尾加上“时间固定效应 - Yes”、“个体固定效应 - Yes”等,这样的做法是有待商榷的,因为这根本就不是固定效应模型。 第二步 : 将第一步回归计算得到的IMR作为控制变量引入原回归方程中。如果IMR显著,说明原回归中存在样本选择偏差,需要使用样本选择模型进行缓解,而其余变量的回归系数则是缓解样本选择偏差后更为稳健的结果;如果IMR不显著,说明原回归存在的样本选择偏差问题不是很严重,不需要使用样本选择模型,当然,使用了也没关系,因为引入控制变量的回归结果可以与原回归结果比较,作为一种形式的稳健性检验。 这里有两点需要注意: 解决方法有两种: 一是对第二步回归的标准误进行校正处理,但标准误的校正方法相对复杂,因此现阶段采用这种解决方案的文献几乎没有; 二是使用极大似然估计(Maximum Likelihood Estimate,MLE),直接对两阶段回归进行整体估计,这种方法在实际应用中使用较多,但存在的问题在于如果样本量太大,计算会非常耗时。因此,考虑到操作的简便性、理解的直观性以及对分布的假设更为宽松,目前国内流行使用的还是两步估计法。 (2)第二步回归使用的样本数目少于第一步。假设所有的解释变量(包括第一步的外生变量)都没有缺失值,仅被解释变量y存在缺失值,那么第一步回归中使用的样本数目是全样本,因为第一步选择方程的被解释变量y_dummy设置为当y取值不为空(包括y取值为0)时y_dummy等于1,y取值为空时y_dummy等于0,故所有样本的y_dummy都有取值,因此都参与了第一步回归。而第二步回归中的被解释变量y存在缺失值,存在缺失值的样本在参与回归时将直接被剔除。因此第二步回归使用的样本数目少于第一步,这也是样本选择模型一个最直观的特征。 相关命令: 研究女性教育(educ)与女性工资(wage)的关系,该例中,基准回归的被解释变量是wage,解释变量是educ和age;选择方程中额外引入了两个外生解释变量married和children。首先,我们还是来先谈一下如何选择排他性变量来处理选择性偏误。了解女性教育对工资的影响,那么这里需要注意到,有些受了教育但也没有参加工作,那这部分样本需要特殊处理。所以,我们就先预测一个女性参加工作的可能性,然后再在那些参加了工作的女性样本中回归工资和教育水平。预测一个女性参加工作的可能性通过age(年龄) education(教育) married(是否结婚) children(孩子数量)。通常认为结婚与孩子的数量一般会与妇女愿不愿出来工作有关,但是与妇女获得工资无关,所以满足排他性和相关性要求,选择为排他性变量。 参与回归的样本数目为1343个,即wage存在缺失值的样本(657个)在回归时直接被drop掉。基准回归中两个解释变量的系数均显著为正,模型拟合程度也较好 在第二阶段回归中,IMR(即lambda)的估计系数为4.2244,但显著性未知,该值等于rho和sigma的乘积,其中:sigma是原方程干扰项的标准差;rho是选择方程干扰项和第二阶段回归干扰项的相关系数。如果rho等于0,表示第二阶段回归中IMR的系数不显著,说明样本选择偏差在原方程中不怎么严重,反之则需要考虑样本选择偏差带来的估计偏误。回归结果的末尾是LR检验,检验的原假设是H0: rho = 0,p值说明至少可以在1%的水平下拒绝原假设,可以认为rho显著不等于0,这说明原模型中确实存在严重的样本选择偏差,基准回归结果不可信。 第二阶段回归中,IMR的回归系数等于4.0016,与MLE方法下的4.2244相差不大,但两步法下IMR回归系数可以直接进行z检验,并且统计结果说明IMR回归系数至少在1%的水平下显著为正,这同时说明原方程中的样本选择偏差问题不可忽视。 第二阶段回归结果中,两个解释变量仍旧显著为正,且大小与基准回归结果相比变化不大,这说明在考虑样本选择偏差的情况下,基准回归结果是可信的。 步骤一:运用probit模型计算影响所考察变量的哑变量的影响因素 步骤二:计算预测:predict y_hat, xb 步骤5:检验方差膨胀因子,通常情况下,VIFs值不超过10,即认为不存在多重共线性问题。 与样本选择模型的两步估计法结果相比,手工两步法估计结果在系数值大小方面没有任何改变,在系数标准误方面变化也不大,从而各个变量的系数显著性保持高度一致。IMR显著,说明原回归中存在样本选择偏差,需要使用样本选择模型进行缓解,而其余变量的回归系数则是缓解样本选择偏差后更为稳健的结果。 Q & A:实现步骤
(1)选择方程的被解释变量是原回归方程中被解释变量y是否被观测到或是否取值的虚拟变量,即y_dummy,当y取值不为空(包括取值为0)时,y_dummy等于1,只有当y_dummy取值为空(missing)时,y_dummy才等于0。关于这一点,现实应用中存在的问题是,即便我们十分清楚存在样本选择偏差,但由于前期数据搜集过程中直接忽视了y取值为空的样本,因此无法采用样本选择模型,因为样本选择模型第一步选择方程使用的是所有样本,包括y取值为空的样本和取值不为空的样本。
(1)两步估计法中第二步回归代入的是第一步回归的结果,因此第一步回归的估计误差也将被代入第二步,造成效率损失,最终导致第二步估计系数的标准误存在偏差,影响p值进而影响系数显著性。stata实现规范命令
heckman y x1 x2 x3, select (x1 x2 z1) (默认使用MLE(最大似然估计),选择方程的被解释变量为y)
heckman y x1 x2 x3, select (x1 x2 z1) twostep mills(newname) (两步法,选择方程的被解释变量为y)
其中,select( )表示写入选择方程,x1 x2为控制变量,z1为外生变量;twostep表示使用两步估计法,默认使用MLE;mills( )表示生成各样本的imr,并以newname作为变量名。stata示例
数据说明
规范命令
webuse womenwk.dta, clear //调用数据
sum age educ married children wage //描述性统计数据
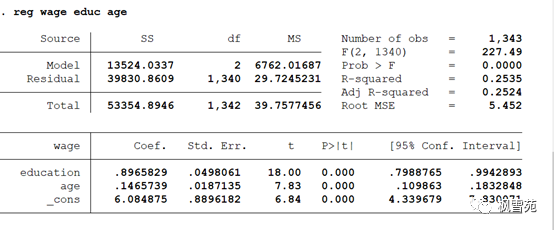
reg wage educ age //简单的模型
est store OLS
*第一种方法 :heckman maximum likelihood
heckman wage educ age, select(married children educ age) //默认最大似然估计
est store HeckMLE
*第二种方法 heckman two-step all-in-one(一步回归)
heckman wage educ age, select(married children educ age) twostep
est store Heck2s
*第二种方法 heckman two-step step-by-step (分步回归)
probit work married children educ age
est store First
predict y_hat, xb //计算拟合值
gen pdf = normalden(y_hat) //概率密度函数
gen cdf = normal(y_hat) //累积分布函数
gen imr = pdf/cdf //计算逆米尔斯比率
reg wage educ age imr if work == 1 //女性工作子样本
est store Second
vif //方差膨胀因子案例操作
OLS基本回归:
Heckman两步法
MLE估计:heckman wage educ age, select(married children educ age)
第二阶段回归结果中,两个解释变量仍旧显著为正,且相较于基准回归结果取值变化不大,说明考虑到样本选择偏差后基准回归结果依然是稳健的。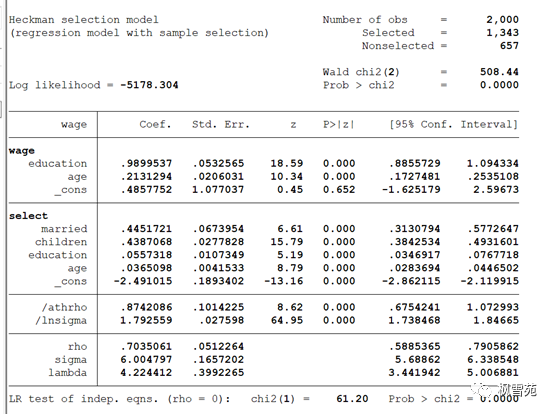
两步法估计:heckman wage educ age, select(married children educ age) twostep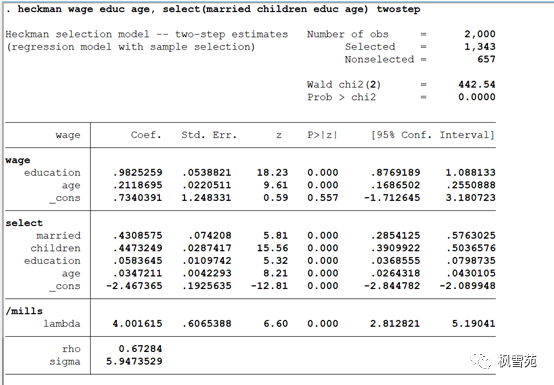
手工完成两步估计法
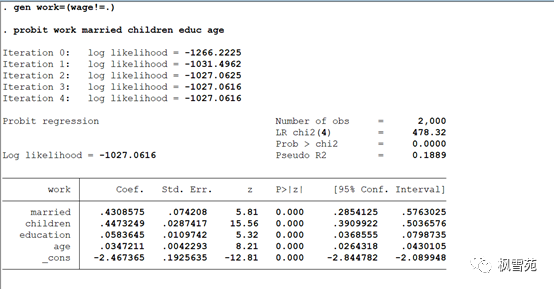
步骤三:计算IMR:gen IMR=normalden(y_hat)/normal(y_hat)
步骤四:最后将生成的逆米尔斯比率IMR引入主要考察模型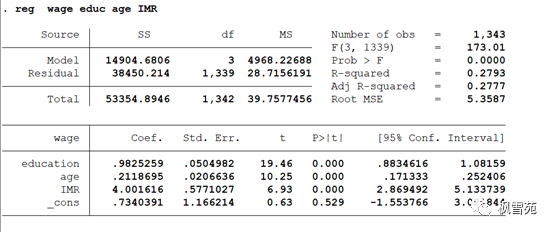

Q:两阶段模型:Heckman模型(处理样本选择问题)和工具变量(处理内生性问题)之间的差异?
各位老师好,我想弄清楚样本选择和内生性之间的差异,以及Heckman模型与工具变量回归的不同之处。话说,样本选择是一种特定形式的内生性是否正确呢?其中,内生变量是个体被处理的可能性吗?另外,在我看来,Heckman模型和 IV 回归都是两阶段模型,第一阶段预测个体被处理的可能性,但它们在实现的目标和假设方面肯定有所不同, 但具体是什么呢?
A1:样本选择是内生性的一种特定形式(参见 Antonakis 等,2010 年对内生性和常见补救措施进行了综述),但内生变量并不是个体被处理的可能性,而是处理变量本身(处理变量的非随机性分配)。内生性,是指错误地确定了因素 X 和因素 Y 之间的因果关系的情况,观察到的“关系”实际上是由于另一个共同影响因素X 和Y的因素Z。换句话说,给定回归模型:
yi=β0+β1xi+...+ϵi
当一个或多个预测变量与模型中的误差项相关时,就会出现内生性, 即当Cov(x,ϵ)≠0时。
内生性的常见原因包括:
-
遗漏变量(一些我们无法测量的东西)
-
动机/选择
-
能力/天赋
-
自选择
-
测量误差(想包括 xj,但我们只观察到了xj*)
-
同时性/双向性(在 5 岁以下儿童中,作为营养状况指标的“对应年龄的体重”与儿童近期是否患病之间的关系可能是同时的。
不同类型的问题需要稍微不同的解决方案,这就是 IV 和 Heckman修正之间的差异所在。尽管这些方法的基本机制存在差异,但他们前提是相同的:即要消除内生性,理想情况下满足排除限制条件(exclusion restriction),即在 IV 情况下有一个或多个工具变量或Heckman情况下有一个影响选择但不影响结果变量的变量。
一方面,当一个或多个变量内生确定的,并且根本没有好的代理变量纳入模型中以消除内生性时,我们应该使用工具变量 (IV) 法,但此时,要记得在整个样本中我们都能够观测到所有协变量和结果变量。另一方面,当存在数据截断时,使用 Heckman 类型的修正方法,此时,在选择变量的值 = 0 的样本中,我们并不能观测到协变量和结果变量。
工具变量 (IV) 方法
使用两阶段最小二乘 (2SLS) 估计量进行 IV 回归的经典计量经济学示例:教育对收入的影响。
Earnings =β0+β1Education+ϵi (1)
在这里,教育成就是内生的,因为它部分取决于个人的动机和能力,这两者也会影响一个人的收入。动机和能力通常无法在家庭或经济调查中得到衡量。因此,方程(1)可以写成包括动机和能力:
Earnings = β0+{β1Education+β2Motivation+β3Ability}+ϵ (2)
由于实际上没有观察到 Motivation和Ability,因此方程(1)可以写为:
Earnings = β0+β1Education+u (3),
其中 u=β2Motivation+β3Ability+ϵ (4)。
因此,通过 OLS估计教育对收入影响的估计是有偏差的。
在实证中,人们将父母的教育作为衡量个体自身教育水平的工具变量。它符合有效工具 (Z) 变量的 3 个要求:
-
Z必须与内生预测变量相关——Cov(z,x)≠0,
-
Z不能与结果变量直接相关——Cov(z,y)=0,并且
-
Z不能与不可观察的 (u) 特征相关(即Z是外生的)——Cov(z,u)=0
当在第一阶段使用父母的教育(MumEducation 和 DadEducation)来估计个体教育(Education),并在第二阶段使用个体教育的预测值(Education^)来估计 Earnings,此时,估计的Earnings是基于不受动机/能力决定的真实Education部分。
Heckman式校正
非随机样本选择是一种特定类型的内生性。在这种情况下,遗漏变量为个体是如何被选入样本的。通常,当遇到样本选择问题时,结果变量只会在样本中“选择变量 =1”时被观测到。此问题也称为“偶然断尾”,解决方法通常称为 Heckman修正。计量经济学的经典例子是已婚妇女的工资:
Wage=β0+β1Education+β2Experience+β3Experience2+ϵ (5)
这里的问题是,Wage仅能在工作的女性群体中观测到,因此起初的估计值会产生偏差,我们不知道对于那些不参与劳动力的人的工资是多少。方程(5)可以重写以表明它是由两个潜在模型共同确定的:
Wage=Xβ′+ϵi (6)
LaborForcei*=Zγ′+νi (7)
即,如果LaborForce>0,Wage=Wage∗;如果LaborForce<=0, Wage=缺失值。
因此,这里的解决方法是使用Probit模型和符合排除约束条件的变量(此处也适用于工具变量)预测第一阶段个体参与劳动力市场的可能性,计算预测的逆米尔斯比率 λ^,在第二阶段,使用 λ^作为模型中的预测变量来估计工资(可以看看Wooldridge 2009)。如果 λ^的系数在统计上等于 0,则表明不存在样本选择问题(内生性),此时OLS 结果是一致的。如果 λ^的系数在统计上显著不等于零,则需要报告来自Heckman修正模型的系数。
A2:应该区分特定的 Heckman样本选择( Heckman sample selection) 模型(仅观测到一类样本和Heckman型校正( Heckman-type corrections)以纠正自选择(适用于两类样本都能被观测到的情况)。后者被称为控制函数法,相当于在第二阶段中包含一个新变量以控制内生性。关于控制函数法,1.控制函数法CF, 处理内生性的广义方法,2.非线性模型及离散内生变量处理利器, 应用计量经济学中的控制函数法!
以一个带有内生虚拟变量D、工具变量Z的方程作为例子:
Y = β+β1D+ε
D = γ+γ1Z+u
两种方法都先运行第一阶段(拿D对Z做回归),IV 使用标准 OLS(即使 D 是虚拟变量),Heckman使用Probit模型。除此之外,主要区别在于他们将第一阶段用于主方程的方式:
-
IV:通过将 D 分解为与 ϵ不相关的部分来消除内生性:Y=β+β1D^+ϵ
-
Heckman:保留内生变量D,但添加第一阶段预测值的函数。对于这种情况,这是一个相当复杂的函数:Y=β+β1D+β2[λ(D^)−λ(−D^)]+ϵ,其中 λ()是逆米尔斯比率。
Heckman过程的优点是它提供了对内生性的直接检验:系数 β2。另一方面,Heckman过程依赖于误差的联合正态性假设,而IV不做任何这样的假设。
所以在误差的联合正态性情况下,控制函数会比IV更有效(特别是如果使用MLE而不是这里的两步法),但如果正态性假设不成立,IV估计会更好。随着研究人员对正态性假设的怀疑越来越多,IV实际上被更频繁地使用。
A3:来自 Heckman、Urzua 和 Vytlacil(2006 年):
选择偏差示例:考虑一项政策对国家GDP的影响。若那些即使在没有该政策的情况下也能做得很好的国家是采纳该政策的国家,那么 OLS 的估计就是有偏差的。
可采用两种主要方法来解决此问题:(a)选择模型和(b)工具变量模型。
选择方法对条件均值的水平进行建模,IV 方法对条件均值的斜率进行建模,IV方法没有识别出选择模型中估计的常数。
The IV approach does not condition on D (the treatment). The selection (control function) estimator identifies the conditional means using control functions.
当使用带有曲率假设的控制函数时,在选择模型中不需要排斥限制条件(不需要Z不等于X)。通过假设误差项分布的函数形式,可以排除结果方程的条件均值等于条件控制函数的可能性,从而可以在没有排除限制的情况下对选择进行修正,还是建议看看Heckman和Navarro(2004)。
参考资料:
https://mp.weixin.qq.com/s/iZJlMAdmu81SWFzZtEWDnA
https://mp.weixin.qq.com/s/VgQWyw9py7Cc1Qb0AX39Tg
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言





这篇文章中提到“选择方程的被解释变量只能是原回归方程中被解释变量y是否被观测到或是否取值的虚拟变量,而不能是其他变量,更不能是解释变量是否取值的虚拟变量。如果第一步回归的被解释变量是原回归中解释变量是否取值的虚拟变量,那么该模型就不再是样本选择模型了,关于这一点,实际应用中经常被搞混。” 那么如果选择方程的被解释变量是原回归方程中解释变量是否取值的虚拟变量,该模型应该是什么模型呢?
34